My new Mac mini just came in and so I now have a Mac that can remain always on and run things like Hazel, Plex, etc. In light of this, I thought I would ask the community:
What is your must have or best Hazel rule? This can be something that saves you tons of time, has a really interesting purpose, or even something that is simply crafted cleverly.
My favorite Hazel rules are the ones that automatically file downloaded or scanned invoices, statements, bills, or other notices. But apart from that I have a set of three rules that watch a folder in Dropbox where all photos from my wife’s iPhone are automatically synced. The Hazel rules import them into Photos on my Mac, moves the imported photos to a folder on my NAS, and then deletes them. (My wife’s phone is logged into my Dropbox account rather than hers, which works for us but might not work for others, and the Dropbox app on her phone autouploads whenever she enters a geofence around our house.) This solves the problem of not having a single Photos library for our family photos.
Desktop cleaner: move all files on the desktop that are older than a week and have not been opened in the last 2 days to a “workbench” folder in documents.
Temp file cleaner: I park some files in the temp folder. Ex, exported selection of slides that I want to email, part of a pdf etc. This rule deletes files older than a week.
Download folder rules: I have a bunch. Depends on your usage. The downloads folder is where most of the Hazel action happens for me.
Download folder:
~ Move all pdf’s and images to Desktop.
~ Some people like to add colored labels to files that have been downloaded longer than 7 days or so.
Desktop:
~ Turn file extensions on for images - I like seeing extensions in filenames.
~ Remove app shortcuts, put their sometimes when an app updates.
~ Some people like to use Hazel to keep their Desktop clean. I do not.
Backups:
~ Various apps keep backups - I copy them into a folder in Dropbox to have a backup of backups.
~ Some apps keep up to 10 backups - I reduce this to 3.
Special case:
~ I have a sort folder where a script examines the name of a file and moves it to a folder based on a student’s initials and the chapter number. The student folders are linked to shared Google folders.
MacSparky talks about an action folder or inbox folder that sorts all of his scanned pdf’s into bills, clients, etc. His pdf’s come to him OCRed, but you can add a rule to OCR a pdf first then sort.
Automatic Trash removal:
~ Hazel will automatically empty the trash based on your preference.
~ App Sweep - Hazel will also remove associated preference files with apps that are placed into the trash.
an IFTTT automation saves all PDFs I receive in my gmail inbox to Dropbox… Even when no email client is running A gmail rule marks the email as read and archives it.
Next, Hazel kicks in to examine the PDF content, rename the file and move it to the archive folder (also on dropbox).
To me, that’s near perfection in terms of automation … I don’t even see the email - and yet the attachment is properly filed away.
What happens if the e-mail was asking for something and the PDF was additional information/something you asked for/etc?
Without examining the context and content of the original mail, it seems to me like this has a very real potential to create voids of actions and information which is antithetical to making things easier. I simply couldn’t use the approach as described.
Is it just that you only ever receive specific PDFs, or is it that you are actually pre-filtering (rather than truly “all”), before processing?
Hi skylumer,
you are of course correct and I should have prefaced my post by saying: this only works for “expected” attachments, i.e. a monthly invoice. For non-recognized PDFs, it leaves them in my action folder for manual processing.
I do something very similar and this single thing makes Hazel invaluable for me. I treat my Desktop like a temporary folder. Like adabbagh, things that have been there over a week unopened get moved, in my case to a folder OldDesktop and will sit in that folder about a month before ultimately being moved to the Trash. OldDesktop is like a safety net. Hazel tags the files that are on the Desktop Yellow -> Green when they are new, then no tag, then Orange -> Red as they are about to be moved off. If my Desktop has become cluttered, the Yellow or Green tags helps me visually locate the more recent files while the Orange or Red flags tell me that those files are about to be moved to the OldDesktop folder. I tag items that I want to keep on the Desktop (like the folder OldDesktop) in Blue and Hazel is set up to ignore these.
Once I started considering my Desktop to be a temporary folder, life became a lot simpler for me and the Desktop metaphor suddenly became very useful. I “know” that if some version of something is on the Desktop it is not the “final” version. The Desktop is just a place where the bits and pieces of things that I am working on live and where I can send downloaded “stuff” that I need at the moment etc. The files there are easily seen, the icons provide visual cues and it is a very easy destination to access. Before Hazel, my Desktop contained a mish-mash of material. Now I “know” that if I left it there, I understood it had a limited lifespan. It is a very easy notion to assimilate.
I have a bunch of rules (sorting, filing, checking PDFs).
As I deal with a lot of PDFs (mostly scanned academic papers), Hazel is first checking if the PDF needs OCR and if it is landscape (so most scanned landscape PDFs are actually two pages, so Hazel makes two portrait pages out of the one landscape page), if OCR is needed it uses Abby Finereader to OCR the PDF. If the PDF is bigger then 30 MB I let abby run over it as it tends to make the file smaller. Then Hazel checks for certain keywords, if they are contained more than 10 times within the PDF it is tagging the file likewise. Then, if everything is finished, the PDF gets imported into Calibre. Word Dokuments, ePubs and Mobi files I put into the action folder are converted to PDF. As I have a dedicated PDF reader and need those files in a certain PDF format (certain size of pages, and page numbers).
For newspaper articles I download and want to read later it renames them with the date within the article and moves it to an iCloud folder which is synced with my tablet and phone.
As for receipts and things like that I have two separate file names and rules according these names – one where I have still to pay something and one simply to archive the bill: When I have to still pay the bill Hazel creates a reminder in the things.app and keeps the file in the folder until I tag it “payed” then it renames it for archive and puts it in DevonThink by year and month (the ones where I already payed are filed right away).
I know you can do it with Apple script and Pages, and I’m going to figure out that tool at some point. But for now, I personally do it with this little shell script which I shamelessly stole from somewhere else, so I left the author info in there:
#!/bin/bash
# Jacob Salmela
# 2016-03-12
# Convert annoying DOCX into PDFs with a right-click
# Run this as an Automator Service
###### SCRIPT #######
for f in "$@"
do
# Get the full file PATH without the extension
filepathWithoutExtension="${f%.*}"
# Convert the DOCX to HTML, which cupsfilter knows how to turn into a PDF
textutil -convert html -output "$filepathWithoutExtension.html" "$f"
retVal=$?
if [ $retVal -ne 0 ]; then
exit $retVal
fi
# Convert the file into a PDF
cupsfilter "$filepathWithoutExtension.html" > "$filepathWithoutExtension.pdf"
retVal=$?
if [ $retVal -ne 0 ]; then
exit $retVal
fi
# Remove the original file and the temporary HTML file, leaving only the PDF
rm "$f" "$filepathWithoutExtension.html" >/dev/null
done
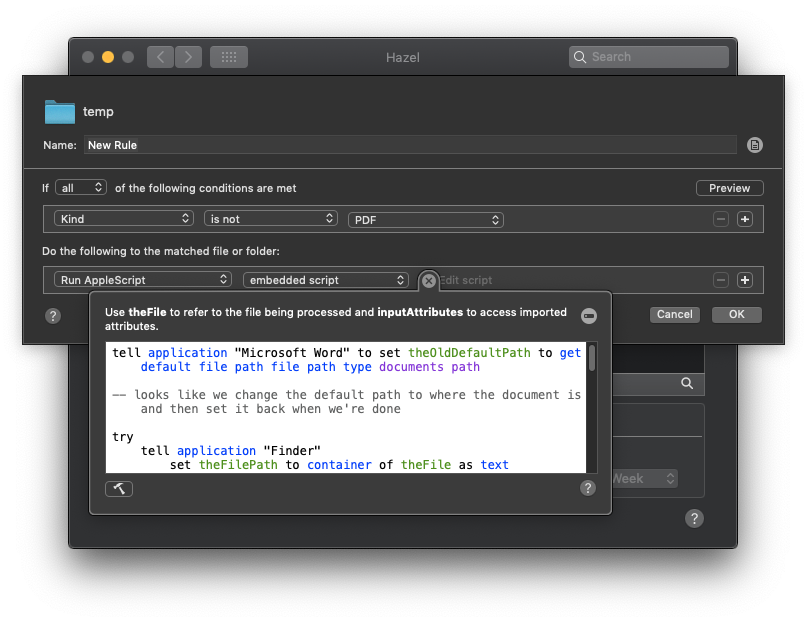
tell application "Microsoft Word" to set theOldDefaultPath to get default file path file path type documents path
-- looks like we change the default path to where the document is and then set it back when we're done
try
tell application "Finder"
set theFilePath to container of theFile as text
set ext to name extension of theFile
set theName to name of theFile
copy length of theName to l
copy length of ext to exl
set n to l - exl - 1
copy characters 1 through n of theName as string to theFilename
set theFilename to theFilename & ".pdf"
tell application "Microsoft Word"
set default file path file path type documents path path theFilePath
open theFile
set theActiveDoc to the active document
save as theActiveDoc file format format PDF file name theFilename
close theActiveDoc
end tell
end tell
end try
try
tell application "Microsoft Word" to set default file path file path type documents path path theOldDefaultPath
end try
The only problem with this approach is that you have to pay for MS Word. I think you can get comparable results by writing an Apple Script using Pages.app for those who don’t want to shell out the dough.
I actually gave your script a try in Hazel and it doesn’t quite work for me. Could you show me how you have your Hazel rule set up? This is what mine looks like:
Luckily I have a word version from my university. I have pretty much the same setup as you do and the script works fine for me, strange… have you given Hazel the permission to open and operate your mac? Which version of MacOsX and Word are you using? (Here Mojave 10.14.2 and Word 16.20)
Yesterday I tried to come up with a script for Pages thought I had one, but it does not work properly – actually randomly one time it worked, but then it stopped working…
I used this hint: Pages to PDF via AppleScript, but could not get it to work with hazel.
Do you know if I can pass page conditions to your shell script? like Page Size, Numbers etc.? Would love to do it with shell, because it would work in the background and there would be no need of an additional program in the front, but the page-size, numbers and pictures do not get transferred properly…
EDIT: Of course there is another option, if you use Calibre – I simply love this app! This is one script to convert epub, mubi, doc and docx to PDF. You can pass certain conditions to calibre at the end. Full documentation here: calibre-ebook-convert
Calibre is amazing. Keeps my digital books sorted!
What if I wanted to convert a bunch of .epub to .mobi or vice versa? I have several versions of one type that I want to convert to the other so I have both versions.
Author > Title > file_name.epub OR file_name.mobi
I guess i could do it via the Calibre converter but need to do that manually. Would rather have Hazel search and find scenarios where only one OR the other is present and convert what is ‘missing’
I think the problem with that is, that you would have to import the newly converted books again into Calibe, because calibre does not notice if a new file was created in its directory even though it is at the right place with the right format.
If you then import the new (lets say) epub to calibre you would have to put the metadata in again for the book and it will be shown as a separate entree in calibre and not as two versions of one book.
I would do batch conversion within calibre: so open calibre, sort books by format, click on all books that have only one format, and then convert them all at once… I think using hazel for that would cause more problems… (sadly as I love both apps very much)
I would do this too, but skip sorting by format and convert all - because when you tell it to convert it asks you what to do with books that already have that format and then you can skip them all with just a click
I use the following script to convert ebooks into other formats. I have 3 versions (1 for each format, mobi, epub and PDF) in a watched folder with the output saved to a final location.
For mobi files I then run the following to email them to Amazon so that they are available in my Kindle.
tell application "Mail"
set newMessage to make new outgoing message with properties {subject:"Hazel to Kindle", content:""}
tell newMessage
set sender to "my email address"
make new to recipient at end of to recipients with properties {address:"?@kindle.com"}
make new attachment with properties {file name:theFile} at after the last paragraph
Finally I load the epub version into Books (my preferred reader app) by having Hazel opening it with Application “Books”.
 A gmail rule marks the email as read and archives it.
A gmail rule marks the email as read and archives it.