…I also have Abby Finereader to OCR but can’t seem to have it OCR the PDFs without showing the Abby UI. Do you know if there is a way to let it OCR without seeing the actual interface, so the process can be done in the background?
As far as I know that is not possible. For me the window stays in the background though – when I am working it does not bother me because I run my apps in full screen… sorry I cannot help you. I just know that devonthink can do background ocr (its the AbbyFinereader engine, too). I am not sure about PDFpenPro, adobe acrobate and alike - maybe one can ocr in the background…
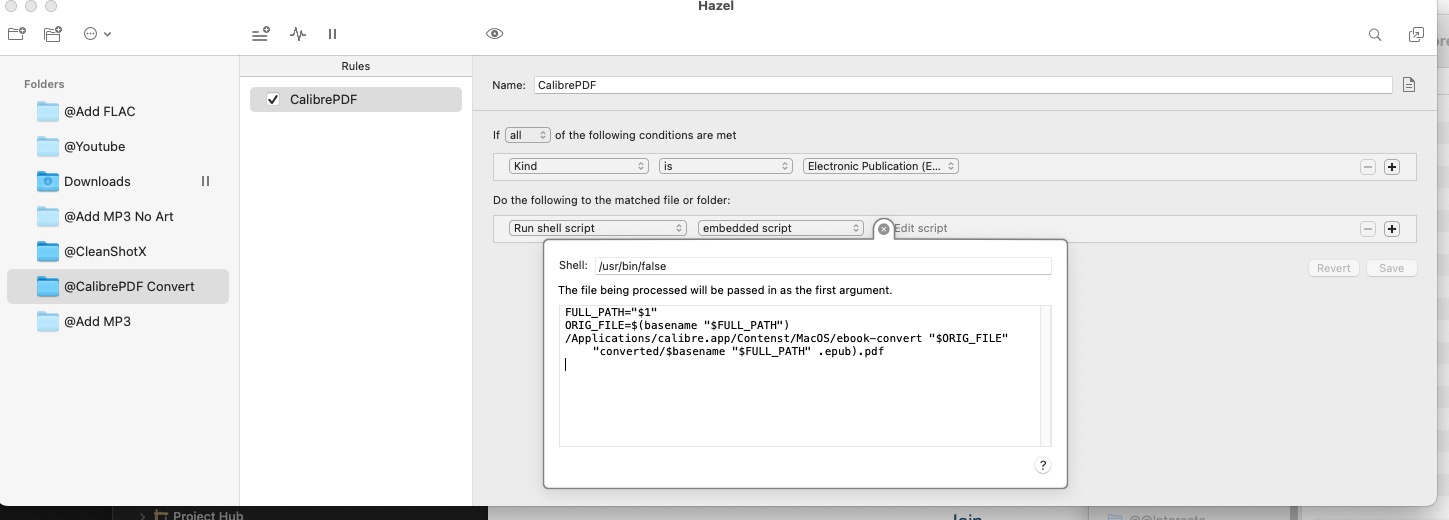
I just bought hazel and I’m trying to get this to work, I set it up to run on a folder so if an epub is found in there it runs your top script, but it doesn’t seem to be working, any suggestions?
I also do a lot of automatic sorting/filing of PDF. I used to process those from download and inbox scanning folder. More recently, since I want to be able to perform those tasks from iPad/iPhone, I have been using a dedicated “Hazel” inbox folder on iCloud.
I save pdf there when using an iOS device (using a shortcut), the process is then done by hazel in “server” mode.
For complex workflow I also use Hazel to send some files to Integromat (this allow for example to build Google Sheets of invoices for tax declaration).
I am finally notified if necessary either by Hazel or Integromat using PushCut.
One of my favorite time-saver rules is a filing, sorting and renaming of PDFs using info from the PDF itself. Info is pulled from either the download URL, or the contents of the PDF.
One example: I have to file sales taxes in multiple states. I download the filing and receipt PDFs to a standard downloads folder. Hazel watches my downloads folder, notes when matching criteria, and renames them (and moves/sorts them by date) all to something uniform for archiving:
/Sales Tax/2019/OH 2019 Q3 sales_tax filing.pdf
Every state uses a completely different naming convention for downloaded files, so this helps me keep my local records tidy with zero effort. I do similar things for CSV report downloads for my online stores.
And since download dates are offset from the actual sales tax filing period timeframe, I can use Hazel’s date offsets, or content matching tokens to grab the proper tax period for the filename.
Hazel has pretty amazing date-modification systems, offering less-common timeframes like quarters in addition to months/days/years/etc. So you can match the filing date in the PDF, have Hazel determine which quarter it was in, and use that for the “Q3” in the filename example.
This could obviously be done for banking, credit card, and other downloaded documents. Especially when the filename needs Include the time period, but it needs to differ from the download/creation date of the downloaded file.
Most of my other Hazel rules are pretty simple, sorting and renaming older files into dated sub folders, things already mentioned or obvious. These complex rules described here are the most useful and also the most satisfying to get working.
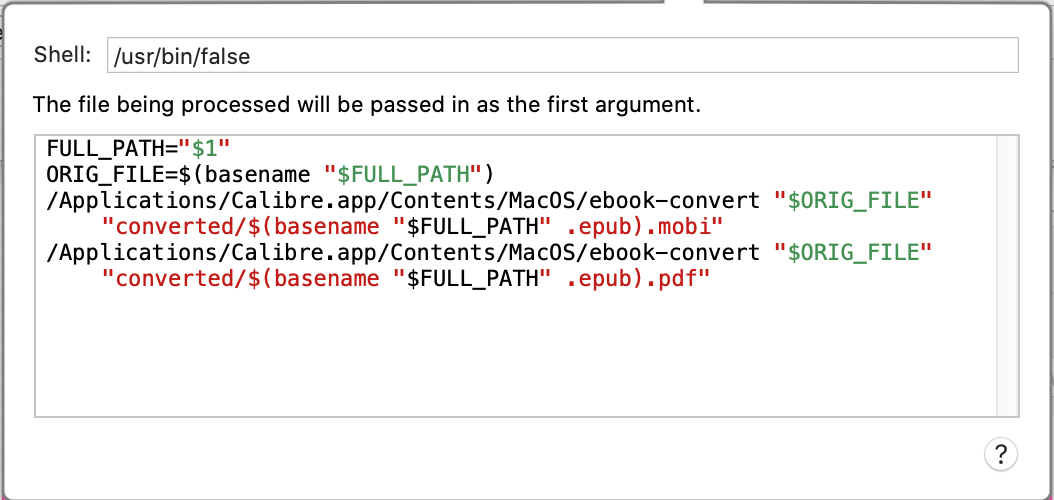
I have been looking for a solution to automatically converting epubs to pdf and came across your awesome post. I am a complete newbie and tried to use your script within Hazel but cannot get it to work.
I created a dedicated folder that hazel is watching for “epub” files (using the “kind” rule) and then asking it to run the shell script you posted. I manually entered the “/usr/bin/false” to make sure I have the right shell path…
Could you be so awesome (and patient) to provide some step-by-step guidance?
I do have have a longer routine that lets you rename a downloaded epub, make a pdf version, save the epub under a category based filing system, then add the epub to Apple Books and the pdf version to DEVONthink for annotation purposes.

 I’m glad to be here as there is so much to find. Looking forward to more automation
I’m glad to be here as there is so much to find. Looking forward to more automation