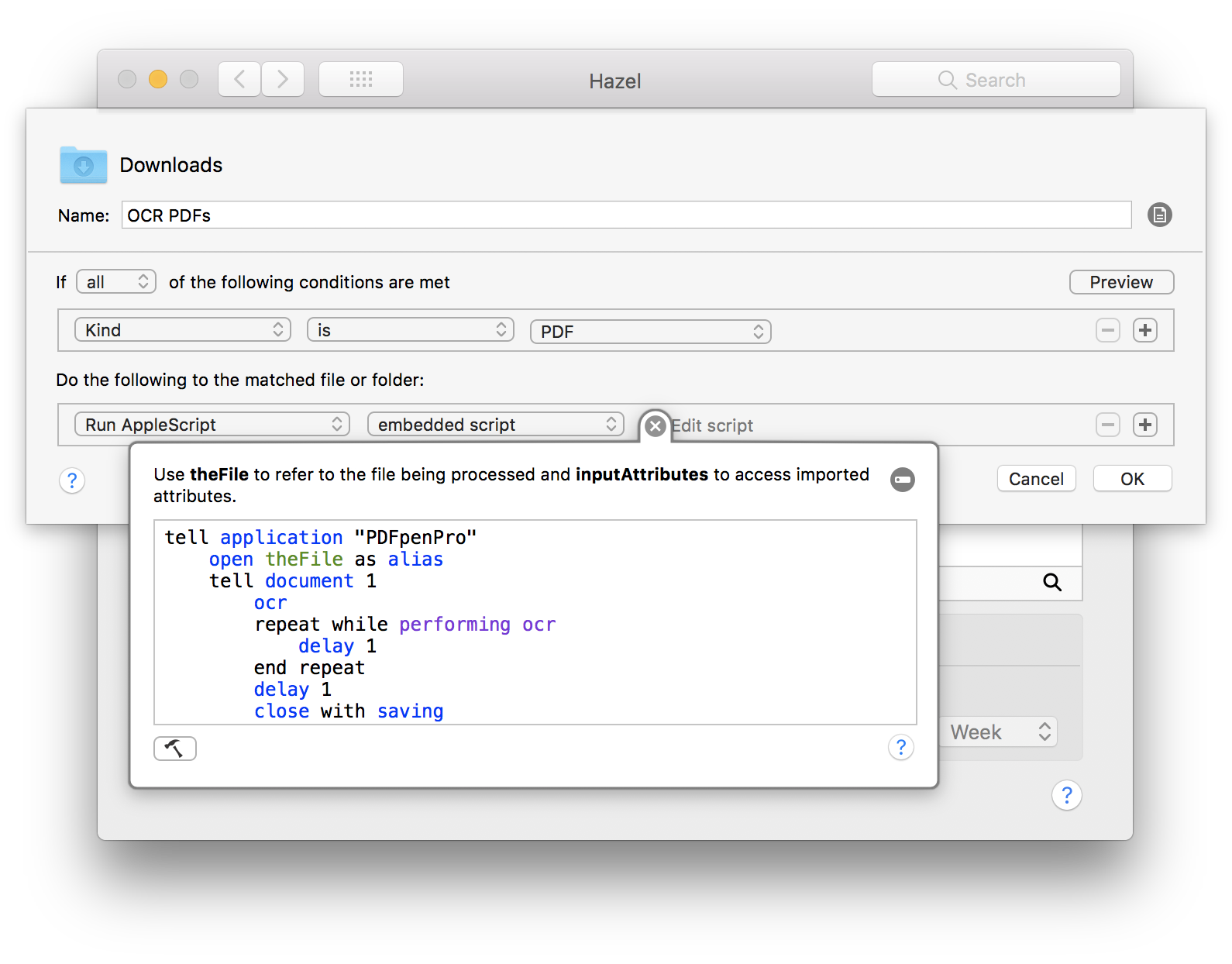
Katie Floyd previously had a fabulous post on her blog detailing how to automatically OCR a PDF, using Hazel and PDFPen Pro. As her blog is no longer available I am sharing her wisdom here:
The first thing you need is a Hazel rule, how you set it up depends on your needs, this is mine:
The rule is very simple, it looks for anything that is a PDF, and runs an embedded AppleScript, documented below.
tell application "PDFpenPro"
open theFile as alias
tell document 1
ocr
repeat while performing ocr
delay 1
end repeat
delay 1
close with saving
end tell
quit
end tell
Full credit to David Sparks and Katie Floyd for originally providing the scripts and ideas!
Thank you very much. The workflow is great. However, when using PDF Pen Pro 10 to perform OCR in long Spanish documents, it tends to get stuck (at least in my experience). In such cases, I have to use Adobe Acrobat. Could the workflow be modified to work with Acrobat for Mac?
I have this same problem, with larger documents hanging at around 60% completed. I don’t own Adobe Acrobat, so I’d be especially interested in a way to automate OCRing a batch of pages – perhaps 30 at a time or so.
More expert scripters can correct me if I’m wrong, but in my understanding Acrobat does not let you manipulate OCR via AppleScript. You may be able to accomplish the goal using Keyboard Maestro that lets you script the UI.
I haven’t compared the two that closely, but I think DEVONthink Pro Office does a better job, especially on documents that are fuzzy. DEVONthink Pro Office uses the Abbyy FineReader OCR engine/software, which is the OCR engine used by the Fujitsu ScanSnap. I use the FineReader Pro scanner app on iOS and it puts other scanner apps OCR to shame.
I’ve used a slightly-modified version of the script that only does the OCR if the PDF requires it (skips if the PDF already has a text layer) and doesn’t close PDFPenPro if another document is open:
tell application "PDFpenPro"
open theFile as alias
-- does the document need to be OCR'd?
get the needs ocr of document 1
if result is true then
tell document 1
ocr
repeat while performing ocr
delay 1
end repeat
delay 1
close with saving
end tell
--In PDFpen, when no documents are open, window 1 is "Preferences"
--If other documents are open, do not close the App.
if name of window 1 is "Preferences" then
tell application "PDFpenPro"
quit
end tell
end if
else
-- Scan Doc was previously OCR'd or is already a text type PDF.
tell document 1
close without saving
end tell
--In PDFpen, when no documents are open, window 1 is "Preferences"
--If other documents are open, do not close the App.
if name of window 1 is "Preferences" then
tell application "PDFpenPro"
quit
end tell
end if
end if
end tell
I offload this sort of processing to PDFPen Pro on my mac mini server and so always close the app when it is finished. When I open it on my Macbook Pro, it remembers what PDFs I was currently working with, so I don’t think the checking of how many files are open would work correctly for me if I was using it there. I figure it would almost always stay open.
Maybe checking for if PDFPen Pro is active prior to opening the file to OCR might be more reliable for those who have files automatically reopen in the app?
The checking if OCRing is necessary is a really nice enhancement. Whilst I think I only send non-OCR’d PDFs to be OCR’d this would negate any need to check on my part and I’m all for that.
I used AppleScript to script the UI in Acrobat X in order to OCR a file.
tell application "Adobe Acrobat Pro"
activate
set theFile to "Macintosh HD:Users:Jim:Documents:img0005.pdf"
open theFile as alias
delay 2
activate
tell application "System Events"
tell application process "Acrobat"
-- run action to OCR
click menu item "OCR_file" of menu 1 of menu item "Action Wizard" of menu 1 of menu bar item "File" of menu bar 1
delay
-- perform the OCR
click button "Next" of window 1
set OCRdone to false
repeat while OCRdone is false
try
set OCRdone to true
click button "Close" of window 1 -- will create error unless OCR is done
on error
set OCRdone to false
end try
end repeat
end tell
keystroke "w" using command down
end tell
quit
end tell
I wanted to mention that Prizmo with the Pro Pack (also available with a SetApp sub) has hooks that Automator can access. I have a similar setup to the ones described above: Hazel watches my Downloads folder, looking for image-only PDFs, and auto OCRs the files. This workflow requires no scripting–perhaps of interest to folks out there, like me, who can’t code, yet!
Thanks for sharing this. I just set this up and tried it out on a couple documents, and the documents I got back looked to be the OCR layer only (i.e., the visible appearance of the document was changed). Do you know if there is a way to get a “normal” OCR’d document via Prizmo and Automator, with the visible part of the PDF appearing unchanged, but containing the invisible OCR layer?
EDIT: serves me right for not digging into this more before posting. There is a setting in the Automator workflow to use "PDF (Image + Searchable Text)
Does anyone have an idea how something similar could be achieved (with Hazel) for Business Cards, where ideally the scan is ocr’ed and then the contact information is added to my contacts and the scan is archived?
Hi David. I’m experienced with Hazel and with OCRing via ScanSnap and PDFpenPro. I’m new to Automator and Prizmo. How do I “hook” Automator into Prizmo? Thanks, Joe