Take a look at this video.
1 Like
Not sure there’s necessarily anything as a direct comparison, but if you search for “prizmo vs pdfpenpro” in your search engine of choice, you’ll find various top 10 app comparisons and some comparison of specific features within particular app reviews.
In terms of PDF Pen Pro recently adding OCR automation features, they have had the option to automate OCR built in there for many years - I can’t remember how long I’ve been using it and Hazel to automate OCR (and other PDF stuff), but easily 5 or 6 years. What Smile did add in v10 this last year, was an in-app batch OCR capability to make things easier.
A familiar sounding voice may have recorded a video about it…
Hope that helps.
1 Like
“In-app batch”
Perhaps that’s what I remember reading. When I typically OCR, I have many PDFs to do, and need a simple iteration mechanism.
Just for the sake of alternatives: I use AbbyFine Reader to automate OCR and especially important for me: to split landscape PDFs (of books) with two pages per landscape page into two portrait pages and OCR the file in one setup. Super useful!
1 Like
Did you ever get an answer on this. I did not know that DevonThink Office Pro could do OCR. I understand that they are almost about to release a new version.
I am just little nervous putting my docs in a container.
Unfortunately it does not really work either. ALWAYS hangs after about 10-20 files.
MACSparky. Can you call your friends at Smile and get them on the fix. It has been unreliable, I mean, DOES NOT WORK, for over a year.
I have reported it multiple times. No Joy.
Have you reported it as an issue to them? Their help desk has been excellent when I’ve had TextExpander issues. That should be the way to raise the issue, not asking someone else to do it on your behalf. That is because it could yet be something very specific to your setup, which could explain why the issue might have persisted for an extended period.
I’m still on version 9 I think and using a script driven approach. Never had any issues, but I’ve a different approach.
1 Like
Guten Tag! Could you point me to the AppleScript to use Abby to automate OCR? I’m using hazel to open PDFPenPro, and would rather use FineReader. This app is on sale now for “Black Friday” and seeing that encouraged me to look at the automator’s forum! Many thanks.
For what it’s worth, there’s a discussion thread on MacScripter for this that also highlights a version difference between app store and direct from Abbyy.
https://macscripter.net/viewtopic.php?id=43516
Otherwise, if you search for abbyy finereader ocr applescript in your favourite search engine, I suspect you’ll find several similar examples in the top results.
Hope that helps.
1 Like
Thanks, Stephen. I did that search but didn’t find a recent script posted. The link you shared looks to solve that problem! Regards!
I know this thread goes back a few years, but I’m having similar issues. I have been using Katie’s OCR script for PDFPenPro with Hazel 4 without issue, and with Hazel 5 since release without issues. I’m on macOS 12.4, Hazel 5.1.2, and PDFPenPro 12.2.3. I suddenly started receiving errors like this, constantly, on every scanned PDF, regardless of source and including old PDFs that were processed successfully in the past, but I manually cleared the OCR layer and tried them again for testing.

I haven’t changed the Hazel rules, config, or the AppleScript. I have tried the newer variations of the script with additional checks to see if PDFs need to be OCR’d, and I have even completed a reinstall of macOS, but the issue persists.
Is anyone else seeing similar issues or have a suggestion to resolve?
My solution to add to the throng.
-
brew install ocrmypdf
-
hazel rule running this bash/zsh script.
if ! grep Font "$1"
then
ocrmypdf -l eng "$1" "$1"
sleep 5
fi
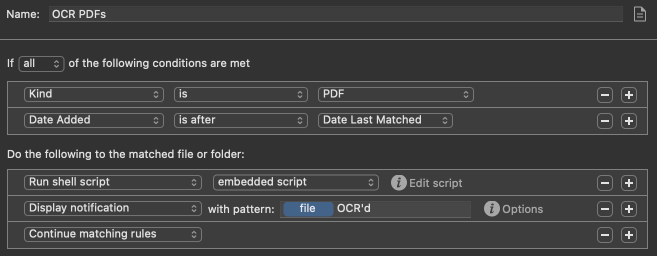
3 Likes
Thanks, I appreciate it. However I have found that I get better results from PDFPenPro than from Tesseract. That’s a fallback option at least.
1 Like
I have taken, for the time being, just import the PDFs into DEVONthink, having them OCRd and then export them back out
I would love to be able to have Hazel watch a folder automate the OCRing with DEVONthink 3.
Let we know if you ever get an answer to your question.
I have taken, for the time being, just import the PDFs into DEVONthink, having them OCRd and then export them back out
I would love to be able to have Hazel watch a folder automate the OCRing with DEVONthink 3.
I have reported the issue to pdfpenpro multiple times and I’ve never really gotten it had a response. Now that they’ve been purchased by nitro the technical support is gotten even worse.
I have Abby find reader installed on my system. Would it be just a simple substitution of the tell XXXApplication to get it working with the different OCR engines.
I have reported it to them multiple times across multiple upgrades to the application and to the operating system. It must be a hard problem to fix, because I really haven’t seen any improvement.
Eventually, it will hang
1 Like
Hi, I am brand new to the automation world. I am a blind Mac User, I use built in VoiceOver to navigate. I have a copy of Prizmo 4 Pro and hazel, just purchased both. Can you provide the Apple script I would need to have hazel run Prizmo on all my documents on my Mac? I know zero about Apple Script or Automator. I was hoping to find someone on this forum with the heart of a teacher that could give me a script that I could copy and paste, or at least write out the instructions like I’m 7 years old. LOL. I chose Prizmo as it is much more accessible with the blind community using Voiceover. I would be happy to make a donation to anyone with a tech help site or to your charity of choice for assistance that results in a ready to go answer. thanks so very much. Brian
Hi Brian I’m sure you’ll find a solution within this community. One issue may be relative unfamiliarity with Prizmo. I had a quick look at their website and couldn’t immediately establish for example whether it had AppleScript support (they seem a very Mac-dedicated developer so hopefully they do). Do you happen to know? Failing that I see one can download a free demo: I’d be happy to take a look if there isn’t already someone out there who’s got this sorted, though I’m not an expert
Hi, Brian,
I am not confident that I can help you script something to OCR all of the documents on your Mac with Hazel, Prizmo, and Apple Script. I’d personally be worried about potential data loss. The solutions discussed above use Hazel to look at a single folder to locate non-OCRed PDFs. If Hazel finds one or more, it then triggers an OCR app (like PDFPEn or Acrobat) to OCR the file(s).
Let me offer an alternative suggestion: If you have a task more complext than monitoring a single folder for PDFs, for example, you wish to batch OCR lots of files across multiple locations on your Mac, I would highly recommend looking at DevonThink. That app allows you to batch OCR files in folders and set up rules specific to particular folders, etc. It appears that DevonThink supports VoiceOver. I have used DevonThink (not with Voice Over) to batch OCR and rename hundreds of PDFs and it has worked very well for me. In sum, DevonThink may be a better option for your project.
That said, let me try to provide some steps for setting up an automation, similar to the ones described above, for Hazel and Prizmo specifically. You no longer need AppleScript to get this to work.
Step 1: Create an Automator Workflow for Prizmo
- Open Automator
- Choose a type for your document: Select “Workflow”
- From the Library, add “Perform OCR” to build your workflow. This is a Prizmo-specific action.
- Set Save Output to Downloads folder
- Review other settings
- Save the Automator workflow and name it and locate it somewhere memorable (you’ll ned to select it in the next step)
Step 2: Create a Hazel Rule to watch your downloads folder and automate the OCR process
- Add Downloads folder to Hazel
- Add rule
- Name rule “Automate OCR” or something memorble
- Set up as follows:
If ALL of the following conditions are met:
- KIND IS PDF
- CONTENTS DO NOT CONTAIN “e”
Do the following to the matched file or folder: - Run Automator Workflow
- Select the .workflow file you created in Step 1.
Comments
-
Prizmo has created a hook that Automator can access. This gets rid of the need to script Prizmo with AppleScript.
-
In step 2, the condition “CONTENTS DO NOT CONTAIN “e”” assumes that any already OCRed pdf will contain an “e.” There are probably better ways to do this, but this is a simple go/no-go test one can do to prevent unnecessarily OCRing a document that is already readable.
-
I’d welcome others’ tips and suggestions. I tried it once, but I haven’t tested this set-up myself.
Good luck!
Dave
(edit: typo)
1 Like