Does anyone have enough experience with TextSoap (@sylumer, perhaps?) to guide me on how to extract multiple regex matches from an OPML (XML) file? I’m hoping to be able to extract the feed title and URL and create a basic two-column CSV file from them.
I’m ok with the regex itself, it’s more how to structure the actions.
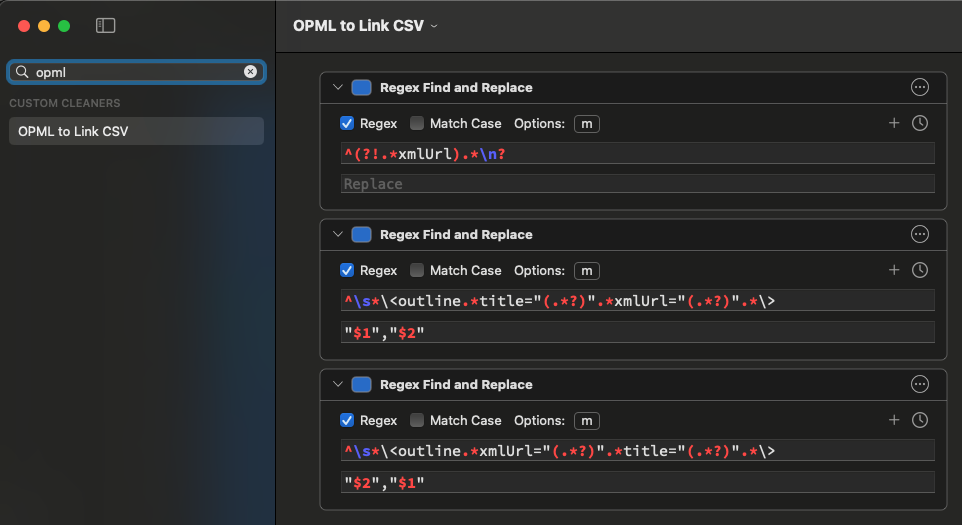
The actions would seem to be the easy bit and the regular expressions the harder part, so just in case here’s what I put together for this.
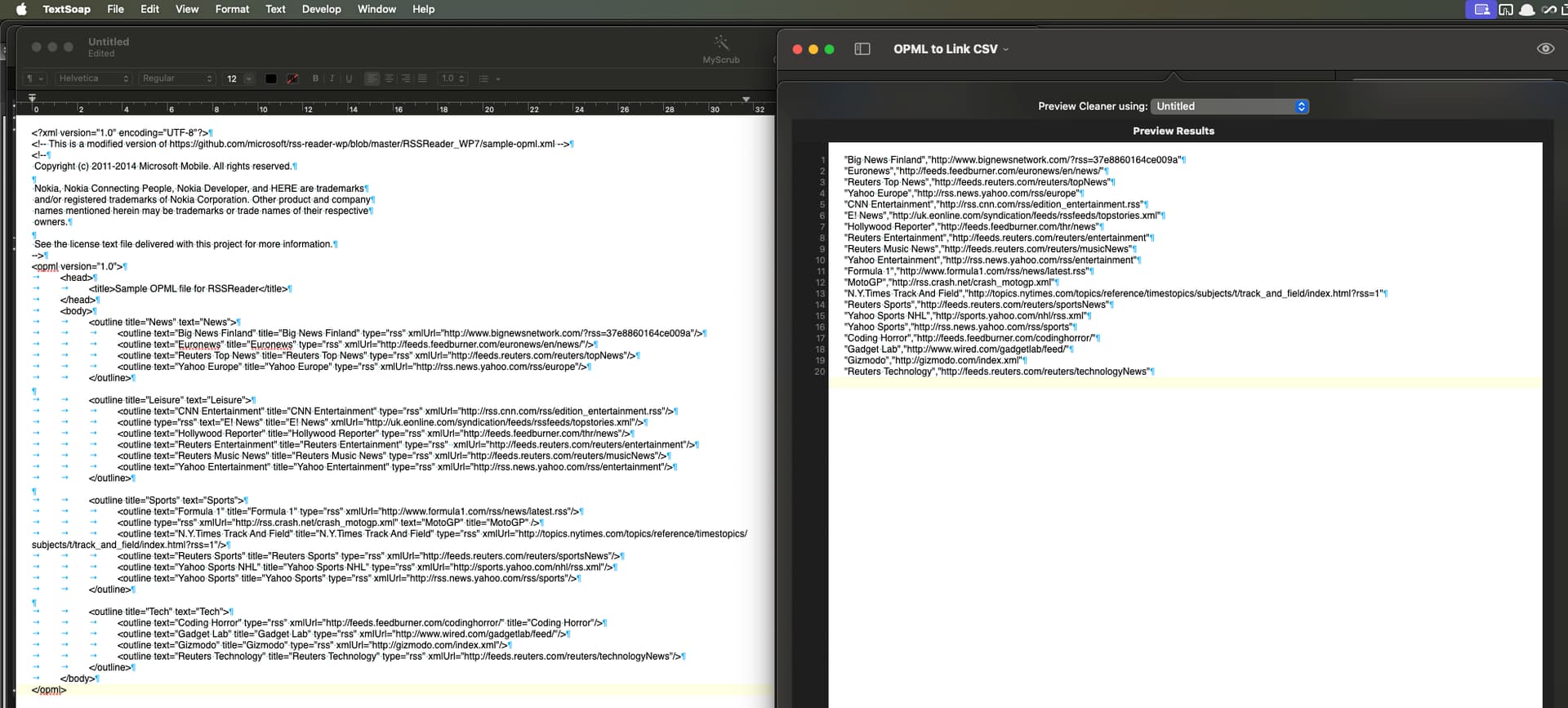
I started out by taking an example OPML file from GitHub and then modifying it to be a little less standardised in the ordering of the attributes within the XML element. The content is the same, but it has a bit of variation.
The first step removes all lines that don’t contain xmlURL.
The second step matches every line where the title comes before the URL and outputs that as a comma separated line with the title first and the URL second, and each of them double quote delimited. This is good practice to avoid any commas in titles, and given we are taking this from XML attributes, any double quotes should already have been escaped.
The third line deals with switched orders where the title comes after the URL in the element. The output order and format is however the same as step 2.
The resulting processing then completes like this.
That’s perfect, thank you very much! I think I got so caught up with thinking I’d need to use an “Extract Text” step that I overlooked using a regular expression to remove the extraneous lines before processing the remainder.
I think I can also achieve this using BBEdit’s Text Factories (and I may try that, just to learn more about them), but I remembered you recommending TextSoap in an Automators podcast and wanted to use this requirement as an excuse to dip my toe in the water.