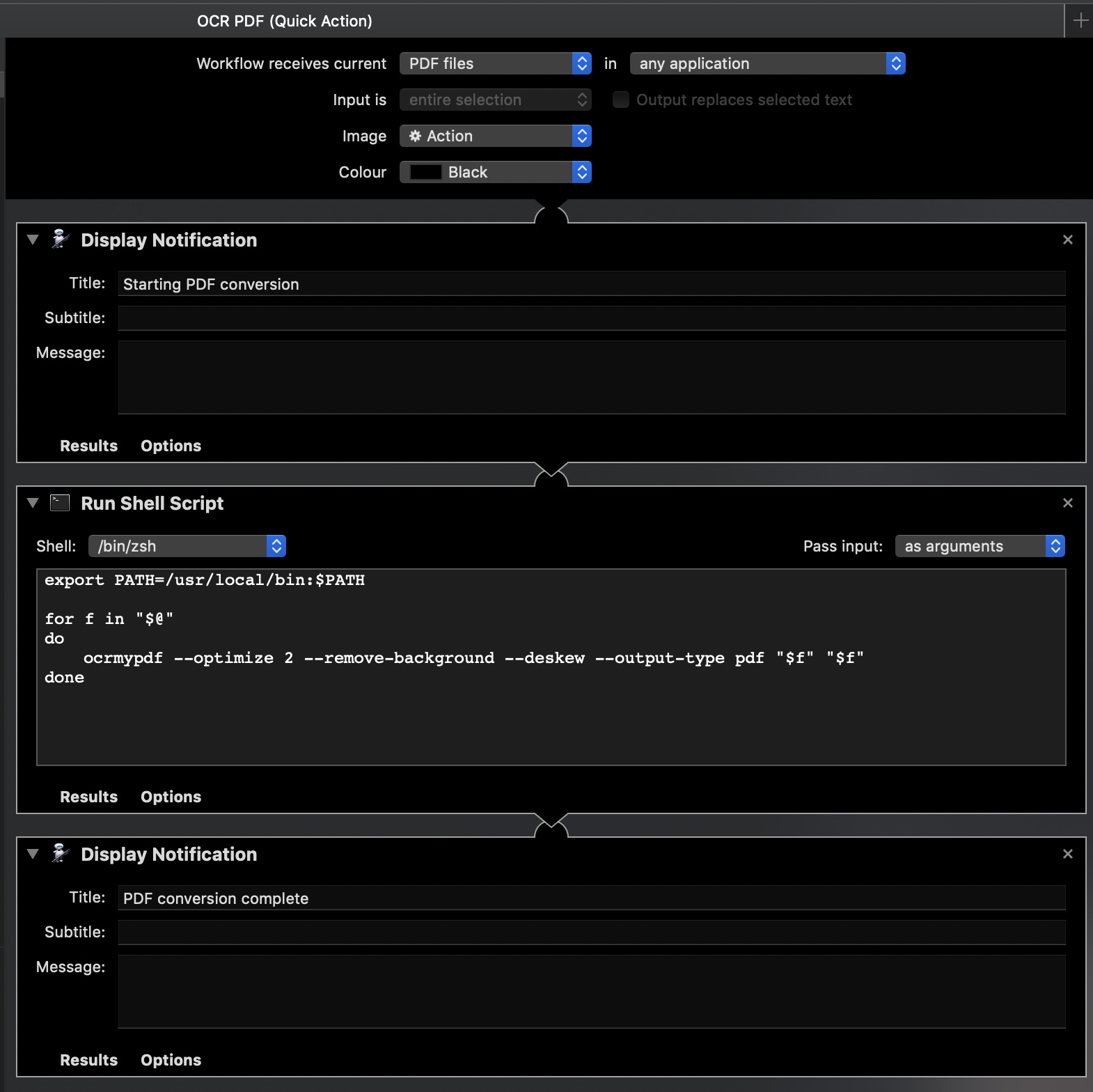
I use the command line program ocrmypdf to ocr scanned files. In order to use it after all my arguments I must put the input filename/path and the output file name and path. I’d like to create an automator services so that I can use the quick actions to run it from finder. My issue is I’m not clear how I get the input files path into my script. Generally when I do this from the CLI I type ocrmypdf --optimize 2 --remove-background --deskew --output-type pdf <input file> <output file>
My issue is when doing through automator I’m unsure of how to pass along the file path to the shell script. I currently have it ‘Get Selected Finder Items’ then ‘Run Shell Script’. ocrmypdf is a python program so I currently have it set the shell as python. Not sure if that is correct either.
Do you mind explaining what the export and for f lines are doing. Trying to understand its if I want to build something else I have an idea actually what is happening
The export is updating the path environment variable being used in the Automator automation to include the path where your PDF utility should be installed to (via HomeBrew most likely). I believe this approach is simply good practice for such scripts (one place to update for key locations of utilities, etc.), but since there’s only one command, probably not as much.
The for takes all of the parameters being passed into the script. There will be one such parameter for each file. They correspond to the paths to those files.
The do loop then executes the OCR command with the $f variable corresponding to each of the file paths that the for found passed in.