Currently having Hazel OCR documents (thank you Katie Floyd) dropped into a folder called “Scanned”. Is there a way within that Hazel rule for it to find certain phrases or words, then rename the file based on that?
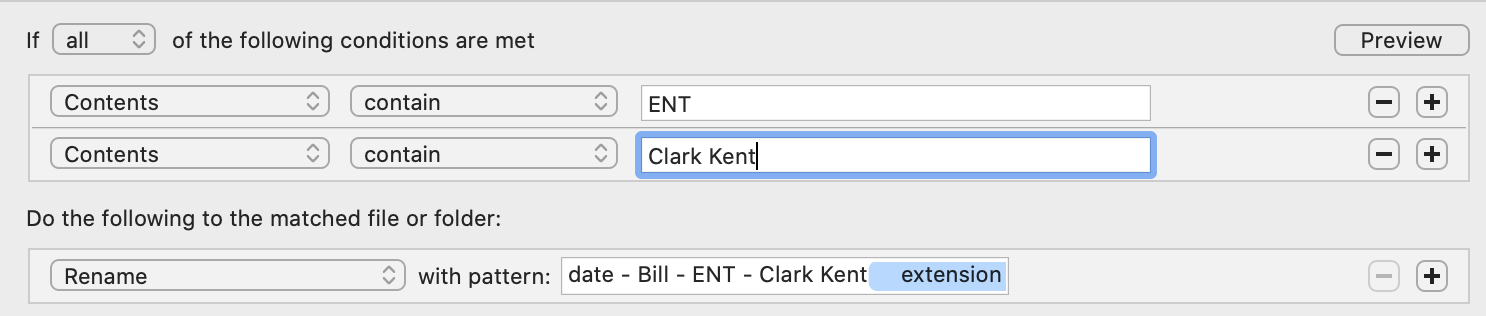
As a work around, I currently have a different Hazel rule looking for keywords within any document in this folder then renaming to the provider seen based on the word search. IE: If it finds ENT and Clark Kent, it changes the name to date - Bill - ENT - Clark Kent. However, we see different types of doctors at different practices. Is there a way for it to find certain keywords and once found rename the file base on the provider?
Example wanted:
If content contains: [Provider Type], Clark Kent; change name to date - Bill - [Provider Type] - Clark Kent
This but also, I want it to find the other doctors we go and name it according to that content. So if it sees ENT, ENT is added in the name change; if it see Pediatrician, Pediatrician is in the name change; etc.
The solution to this is going to be to have rules to cover every specific case. Not exactly foolproof, but if it covers all cases and the OCR is accurate, then it will in fact be correct each time.
The next stage will involve systems that utilise machine learning. You will train the systems on how to name different types of receipts, documents, etc., and the system will effectively create its own rules. These sorts of systems are beginning to emerge in the enterprise, so it will just be a matter of time before this sort of thing will be prevalent in the consumer space.
Look into the rule criteria Contents > Contains Match
That will allow you to “token-ize” the keyword match, and use it for the name change in the actions.
If the keyword is in the same context every time, it will be much easier to build the rule. Otherwise you may need to have a lot of rules and/or conditions.
With PDFs, sometimes it’s best to drag, copy, and paste the relevant section into the criteria field and build your “contains match” criteria from there, so it picks up the funky PDF text sequences.