Hi there,
I’m trying to have Hazel rename invoices issued to multiple clients. Every invoice will have a different client name, but the name location remains the same. I’m attaching one here as an example, perhaps it helps. The section of the variable name is in red.
I have made some progress, but I’m not quite there yet, and maybe someone knows how to get it to work.
Basically, I’m telling Hazel to get the Date of the invoice (which works just fine) and also the name of the client. Then, I want it to use those details to rename the PDF, which I can partially get it to do. The date works just fine, and I also get the name of the client, but for some reason, I also get the rest of the information on the same line as the client name, meaning, I get something like this "
Do you have any idea how this can be done?
Thank you so much.

It seems like your example line has been trimmed out, but perhaps a regular expression might b an option?
Hi there!
Sorry for the late reply.
Yeah, I trimmed it, because it contains personal information. Under the red line is just the name of the person the invoice was issued to. What happens is, with my current Hazel setting, the result is the date (which correct, followed by the address (the info to the left, on the same line as the name), followed by the name (which is correct).
To be clear, the resulting string of text should be “YYYYMMDD Name of Guest”, but I get “YYYYMMDD Address Name of Guest”.
Currently, I’m using “Contents” - “contain match” - “… Anything” - match the 3rd occurrence from the beginning.
Any ideas how this could work?
Thank you so much!
Okay, I think I understand, but this is hard to do without an actual PDF to work from.
I created a PDF based roughly on the upper layout you have that hopefully illustrates something that will work, or at least get closer for you.

You have ways of picking out the other required data items, so it is just getting the name. Given you don’t have any other key text markers on the PDF, and the contents comes out as just a string of text - nothing positional, I have had to assume that people will have two names. I know this isn’t always true (e.g. Lee Van Cleef"). If you did need something more advanced, then maybe using an automation that taps an LLM to extract the name from a line of text for you could work? The next version of macOS may just allow you to do that in a relatively secure way - it would be worth experimenting when you have it available. Until then I’ll continue on the two name basis.
Here is the basic structure I tried.
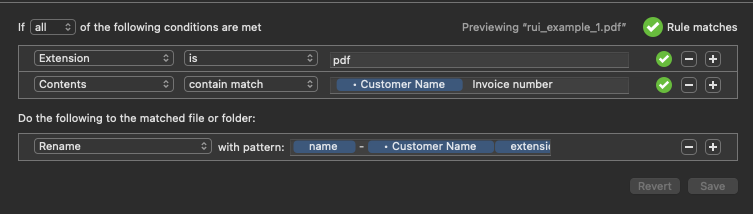
This first matches the file as a PDF, then a content contains match using a custom match followed by “ Invoice number”, “Invoice number” coming immediately after the customer name - hence we have something we can use as an end delimiter. The space will match any whitespace on the PDF including newlines.
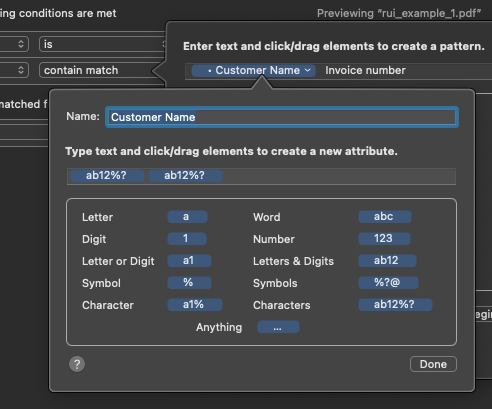
Customer name is a custom text attribute, and rather than matching the third line I’m just taking the first match, Invoice number only appearing once.
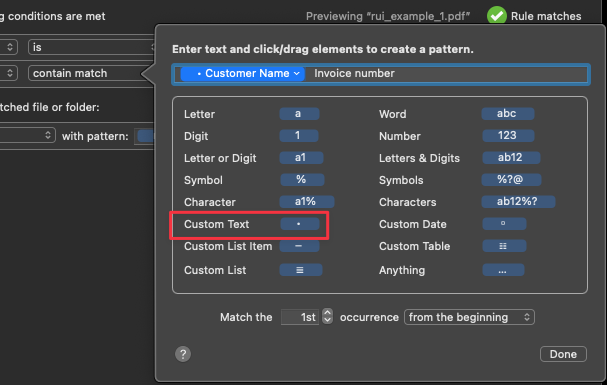
If I select the drop down on the attribute to edit it, you can see it is just defined as characters, space, characters - as per my earlier note on two names for the customer name.
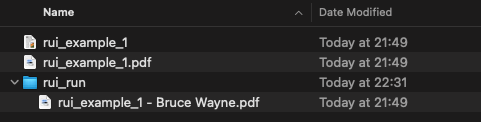
If I drop the outer PDF into the inner watched folder with this rule, it puts the customer name into the file name as per the action of the rule.
On the assumption you can’t modify the invoice template for future use to help you, and noting that pulling the text from a PDF just gives you text, not layout position, I think your best future-proofed option will be to bring some appropriately secure AI into the mix. You could do something now and have a script run that tags the file or adds the name to a comment and Hazel continues processing with that. However, if you had a finite number of customer names, and/or you had a customer ID from one of the redacted regions on your PDF, that could be looked up from a list, then you potentially have another option there.
Hope that helps.