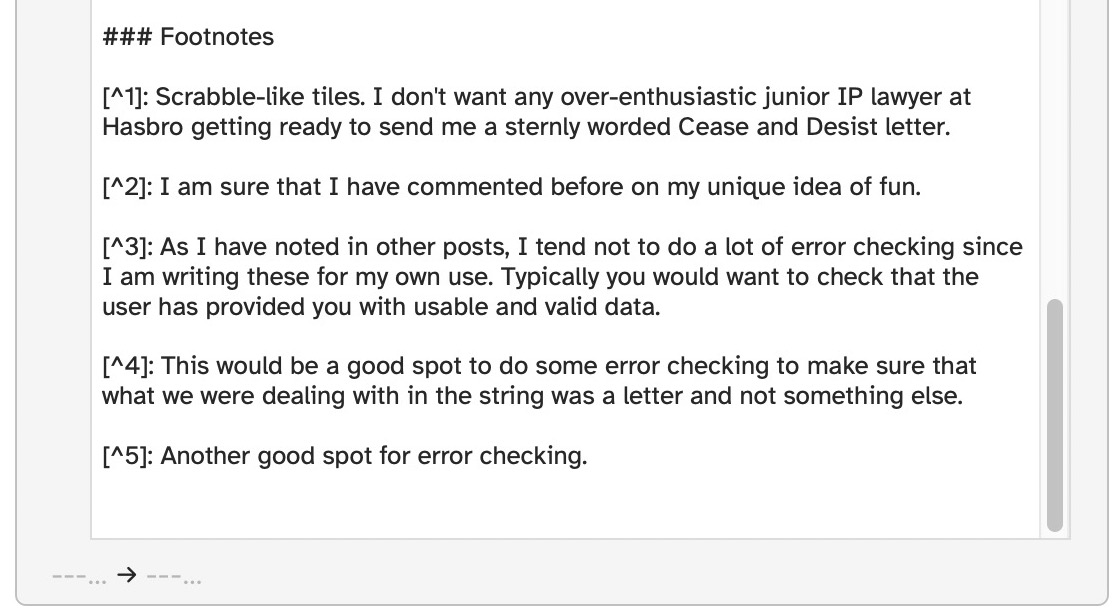
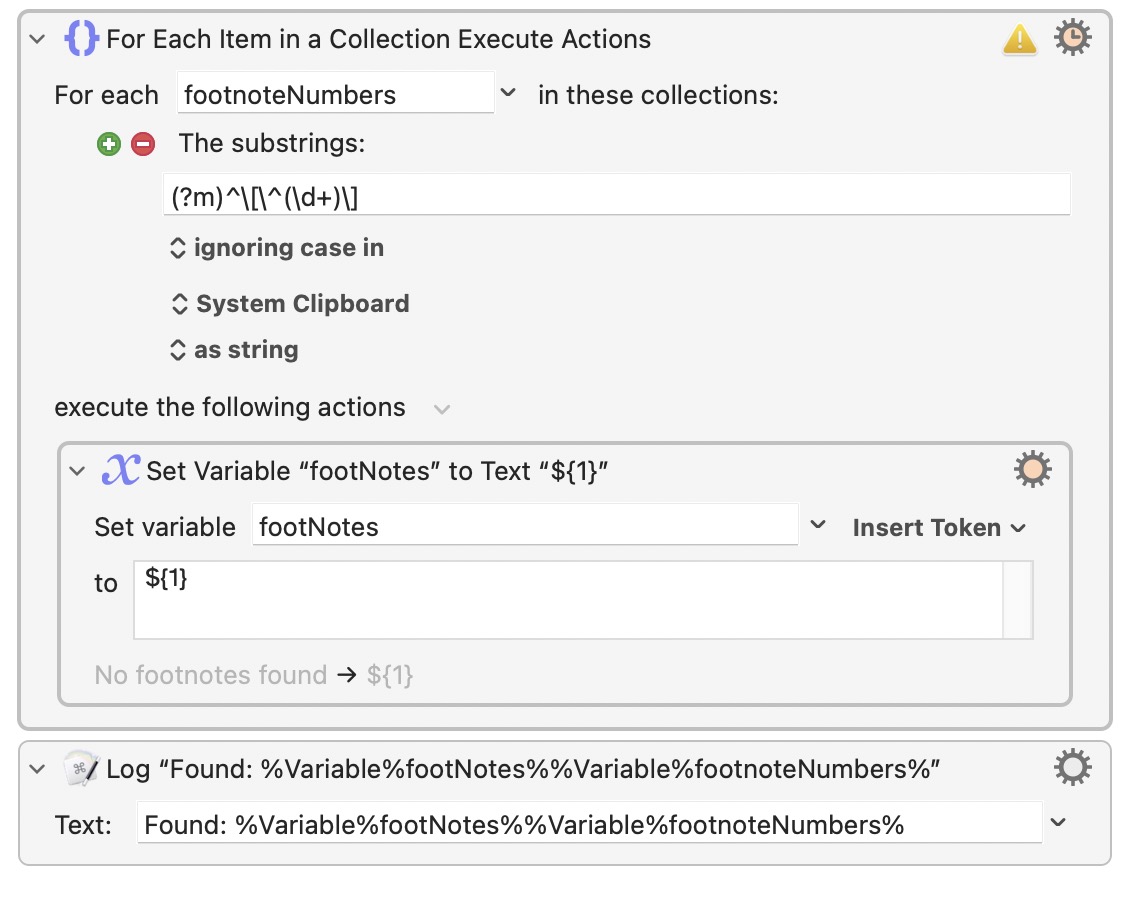
This multiline regex is in a For Each action. It should catch them all but it only seems to catch one. As well, the footNotes variable is never changed when I execute this.
2023-03-05 06:48:48 Execute macro “Footnote” from trigger Editor
2023-03-05 06:48:48 Log: Found: No footnotes found1
Anyone have any insight into why this isn’t working?
My assumption was that the For Each would capture each group and iterate over them. So the value of footNoteNumbers should be 5 and not 1. Also, footNotes should be set to $1 (I know that is not the correct way to do that) as indicated in the action but it doesn’t get changed when this executes.
Did you check the warning on your for loop? Clicking on it should give you the details in a pop-up.
It is a collection, so I would not expect it to have a value of 5, but rather a collection of values corresponding to "[^1]", "[^2]", "[^3]", "[^4]", "[^5]".
It isn’t doing that because nowhere is that specified when matching - further details below.
Here is a macro that I think works for the sort of thing you want to do. I’ve reproduced and included the text from your screenshot in the macro, and have it collating and outputting to the screen to save you digging into the log - since it is purely meant as an example.
It looks to me like you are missing the search of the collection item to work with the capture group. Take a look at the example #2 in the Keyboard Maestro Wiki page on using regular expressions. That is very close yo what you had set out, but incorporates the additional search.
My understanding is that your for each and collection are feeding items in that have been matched, but because it is ‘have’ and the capture group was not recorded to a variable at that stage, to use the capture group, you effectively need to reapply the regular expression matching to the item, and subsequently grab the capture group and store it in a variable.
As is, I think you could therefore drop the match of the trailing square bracket in the expressions. You might need to include it if you were switching out your digit matching for character matching - Markdown footnote IDs do not need to be numeric, they can certainly be alphanumeric, but I’m not sure off the top of my head what symbols, if any, are valid Markdown footnote ID characters.
The capture group is the number inside the match. So it matches [^1] but captures 1. They are a bugger to read and process
Really? Well that explains my confusion.
I didn’t even see it. I’ll rebuild it and see what it is unhappy about. The UI sizes in KB may have worked back “in the day” but even on my Macbook Air it is getting a might small to read.
Thanks very much. I think I might understand the odd structure for the example.
I am using KB because the app I am working with is an Electron app but this has been annoying enough that I may switch editors. I wrote the same code in Alfred in about ten minutes and it worked the first time.
I think you are getting a little mixed up with regular expression matches and regular expression capture groups on that point.
The variable footNoteNumbers isn’t receiving a capture group, it is the variable assigned the value of each regular expression match, in order.
The capture group in the regular expression is (d+), and would correspond to the digit within the match, but this is not what is mapped to the variable. In fact, nothing is done with the group during the collection generation. It is effectively discarded.
Because it is the match, and not the capture group, footNoteNumbers would be each item in turn matched by (?m)^\[\^(\d+)\], and so would be [^1] for the first item, [^2] for the second, and so on, rather than the 1, 2, etc. you seem to have expected in that last statement.
Yes and no. I was getting KB to show that the capture values were what it was putting into the variables in an earlier iteration. I’ve been through a few trying to get it to work.
Its this sort of thing that has been making this process a little more difficult than it should have been
My aim here has been trying to understand the underlying process so while I was looking through the examples I didn’t just blindly follow them as that isn’t how I learn. The docs are also not really clear on this.
Your comments have cleared up how this works. So thanks again.
I might email Peter and see why it is that the code works this way.