Hello All.
Assistance would be much appreciated - I have a prototype AppleScript file that successfully reads the CSV file and splits the required field. At the moment it just logs the data to the console.
Two issues:
Issue 1 - It fails once run with the error
Result:
error "Can’t get item 1 of {}." number -1728 from item 1 of {}
Which will be something basic but I can’t see what it is.
Issue 2 -
What is the best way to write the output to a new csv file with the same name & path as the one chosen by the user but with the suffix “- processed” appended? e.g. test.csv becomes test-processed.csv
Here is the prototype file - comments and suggestions very welcome.
-- Open CSV File and import to list
-- select the file
set theFile to (choose file of type {"public.comma-separated-values-text"} with prompt "Select the CSV file")
-- read the file contents
set f to read theFile
-- break the file into rows (paragraphs)
repeat with row in ((paragraphs of f))
-- parse the row into comma-delimited fields
set fields to parseCSV(row as text)
-- now we have a line of data:
set payAmount to item 1 of fields
set paySortCode to characters 1 through 6 of item 2 of fields
set payAccount to characters -8 through -1 of item 2 of fields
set payName to item 3 of fields
set payRef to item 5 of fields
-- now do something with the data:
log payAmount & " " & paySortCode & " " & payAccount & " " & payName & " " & payRef
end repeat
-- subroutine to process the CSV and make the list
on parseCSV(theText)
set {od, my text item delimiters} to {my text item delimiters, ","}
set parsedText to text items of theText
set my text item delimiters to od
return parsedText
end parseCSV
Background: The accounts package spits out a csv file. Unfortunately the output contains a single field that I need to split into two fields (the sort code and the account number) so that I can import it into the bank without worrying about errors creeping in as someone hand edits a payment file!!!
For completeness here is the full events log from the ScriptEditor:
tell application "Script Editor"
choose file of type {"public.comma-separated-values-text"} with prompt "Select the CSV file"
end tell
tell current application
read alias "Macintosh HD:Users:philiproberts:Downloads:test.csv"
(*22.64 123456 12345678 Fred Bloggs MCI Logistics*)
(*88.64 654321 87654321 Elephant Enterprises 88246 MCI*)
Result:
error "Can’t get item 1 of {}." number -1728 from item 1 of {}
and the sample csv file (yes there is an empty 4th field)
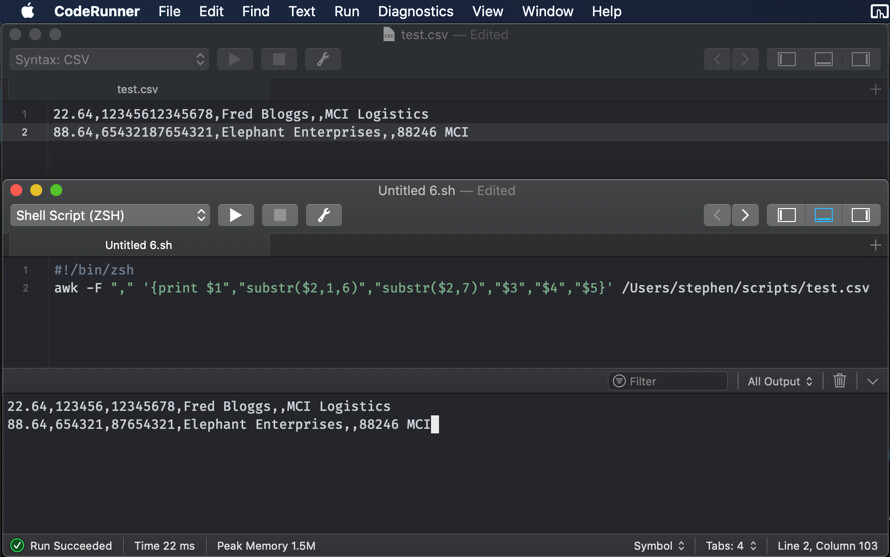
22.64,12345612345678,Fred Bloggs,,MCI Logistics
88.64,65432187654321,Elephant Enterprises,,88246 MCI
 )
)