I have a small Brother desktop scanner which works well for my limited needs. It, however, has an occasional tendency to skew the pages when scanning. PDFPen does a good job of correcting the skew but I don’t want to have to manually open it up each time I scan something.
I was hoping PDFPen’s applescript dictionary would allow me to script it but alas that functionality isn’t exposed.
Is anyone aware of an app / utility /scripting library which offers this capability that I can check out?
You could use your favourite tool (sips, ImageMagick, Automator, etc.) to split a PDF to images. Then straighten your images, using deskew, and convert them back to a single PDF using your preferred conversion tool again.
I implement OCRmyPDF in my Paperless workflow (ala @MacSparky) using Hazel and it’s scripting abilities. I have set up simple one-time workflows in Hazel that are triggered by a tag and then apply a certain PDF-taming script to that file. For instance, I have set up Hazel rules to OCR, compress, de-skew and correct page rotation of PDFs, all based on tags as triggers. This allows case-by-case clean up of PDFs. See the MPU post below for an OCR-compress pipeline. In retrospect, I could have used OCRmyPDF for both of these actions. The rabbit hole is very deep when it comes to processing images and PDFs!
@dexagram to simplify this, I’ll give an example and then show how to automate it. First you will need to brew install ocrmypdf. Then you can run the following command in the terminal to deskew a PDF without applying OCR. I’ve been mucking around with this and it works well. Incidentally, if you wanted to run OCR, just remove the --tesseract-timeout=0.
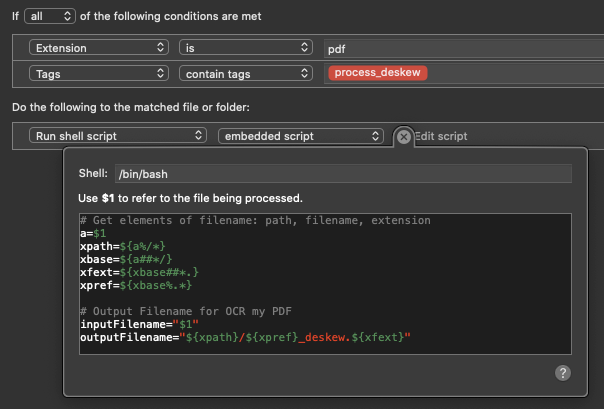
To automate it, I trigger the Hazel rule using tags, and applying that tag to a file in order for Hazel to pick it up.
The full script is
# Get elements of filename: path, filename, extension
a=$1
xpath=${a%/*}
xbase=${a##*/}
xfext=${xbase##*.}
xpref=${xbase%.*}
# Output Filename for OCR my PDF
inputFilename="$1"
outputFilename="${xpath}/${xpref}_deskew.${xfext}"
# Process OCR my PDF
ocrmypdf "${inputFilename}" "${outputFilename}" --deskew --tesseract-timeout=0
# Delete Original File
rm "$1"
# Rename the processed file back to it's original name
mv "${outputFilename}" "$1"