My Google-fu is failing me so please help me out.
I wanted to rename files based on partial texts that I extract from the filename. These partial texts are used as keys on the .json file to provide the new name.
Example file
file1_2020-01-08_some-other-info.pdf
I’m extracting file1 from that filename. This is a simplified example as the partial text may contain letter, numbers, underscores and dots. I have this covered via Javascript.
Now, I have a .json file with something like this:
{
"file1" : "File One",
"file2" : "File Two",
"file3" : "File Three"
...
}
Now, I want to load the contents of this .json file so I can match file1 and get File One, preferably in Javascript. But any other option will do.
Any ideas?
I haven’t tested this (and I’m no expert!), but I think it should be possible to use the ‘Run Javascript’ action to do this (https://www.noodlesoft.com/manual/hazel/attributes-actions/using-applescript-or-javascript/).
You would need to add the custom token part of the file name you are extracting as an input attribute, then return the file name to Hazel (instructions for both of these are on the page above).
From there you could use the custom attribute exported by the script to rename the first file.
Thanks, I’ve already figured out the token extraction part.
What I wanted to do is based on the token – file1 – is to read another file that stores the descriptive value and use that value as a folder and move the file there.
Here’s what I wanted to achieve basically:
file1_2020-01-08_some-other-info.pdf --> /File One/file1_2020-01-08_some-other-info.pdf
file1_2020-01-09_more-other-info.pdf --> /File One/file1_2020-01-09_more-other-info.pdf
file2_2020-01-08_some-other-info.pdf --> /File Two/file2_2020-01-08_some-other-info.pdf
otherfile_2020-01-09_more-other-info.pdf --> /Other/otherfile_2020-01-09_more-other-info.pdf
It sounds like you want to not only rename files, but also sort / move them into sub-folders, based on the content of another file?
If all else fails, you could almost certainly move the files using a shell script which would take the extracted “token” and then use it to look at the reference file to see where it should be moved.
I don’t know JavaScript, unfortunately, so I can’t help you with that part, but I could help with the shell script if you don’t find another alternative.
Ah, sorry, I don’t think I was really clear!
You can also use Javascript as part of the actions AFTER the rule is matched, and that Javascript can export that back to Hazel.
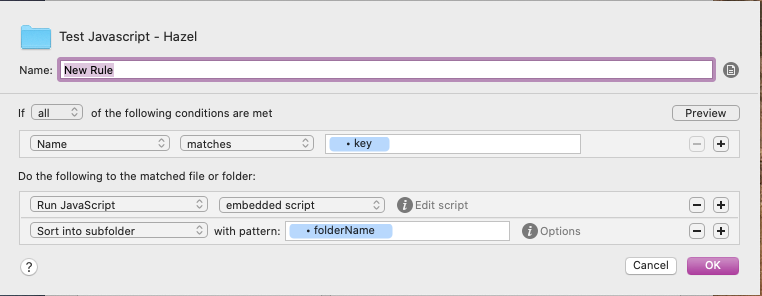
So, you can do something like this:
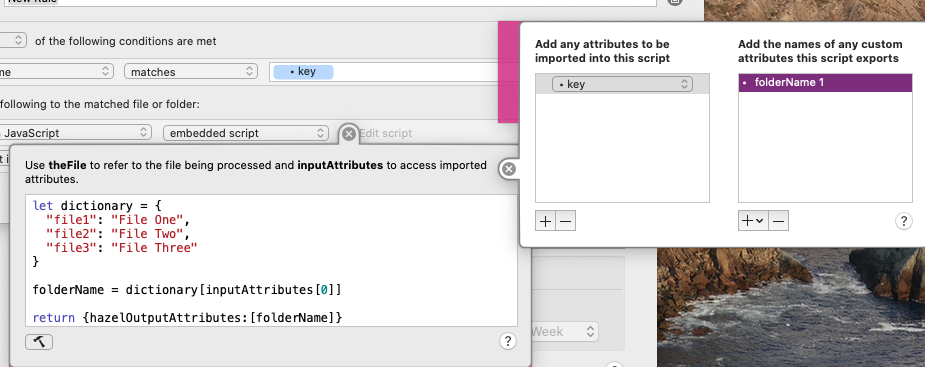
where the embedded script is something like this (note in particular the custom attributes that are exported; these need to be added manually as well):
The part I’m not sure about is whether you can read that JSON file into Hazel. I’m sure it’s possible somehow–the thing that comes to mind is to use a shell script to get its contents and then export THAT into the Javascript script–but maintaining it directly in the script may also be a possibility anyway, depending on the use case?
[[Just ignore that ‘1’ on the end of the file name in the second screenshot; that seems to be some Hazel weirdness on Catalina, I think…]]
I see. Yes, this requires embedding the dictionary into to script, which I didn’t want to do because I would have to keep updating the script every time I need to add an entry.
Good thing is after much more searching (for JXA instead of Javascript) I found a way to load a .json file into a variable.
Here’s the excerpt.
var app = Application.currentApplication()
app.includeStandardAdditions = true
function readFile(theFile) {
return app.read(Path(theFile))
}
function load_json_file(path_to_file) {
var dict = JSON.parse(readFile(path_to_file))
return dict
}
var dict = load_json_file('/path/to/file.json')
// key = token extracted from file
folderName = dict[key]
Hope someone may find this useful.
1 Like