Realise this is a borderline-FAQ but would really appreciate help with crafting a Regex. This is for use in Keyboard Maestro so I think needs to be ICU-flavour regex.
Given the following string
“[preamble text] see [topic] in Chapter [#] p. XXXX”
I want to generate capture groups for [topic] and [#]
The source text is pasted into the clipboard from a PDF and both [preamble text] and [topic] are multi-word phrases that may include line breaks
I think you might struggle there. The word “see” could appear multiple times in [preamble text] and in [topic], so how would you know for sure where one ends and the other begins? “see” isn’t exactly an uncommon word.
Thanks Stephen. Good point, though I am using this to slightly streamline an essentially manual process of book editing so will be supervising and can intervene if it’s tripped up in this way. If we ignore this specific scenario is there a solution?
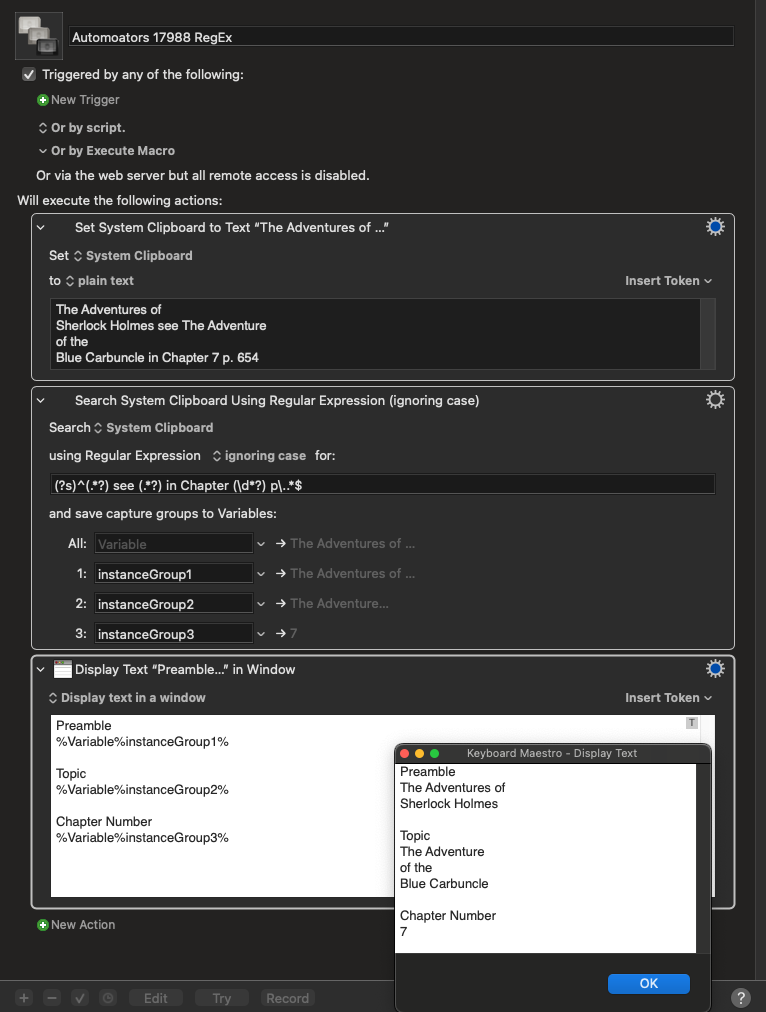
Okay, if you assume any time that occurs you will take manual action, then I think this might suffice.
(?s)^(.*?) see (.*?) in Chapter (\d*?) p\..*$
It sets . to match newlines then matches based on the boundary conditions you specified, though I set the chapter match to be multiple digits explicitly.
Here’s how it looked with a test I ran putting each match into a variable.
Hopefully that lines up to your processing needs, but I would consider adding something in to check if there are multiple " see " occurrences, and if there are, it then pops up some sort of option to identify where the sections should be broken and then processes based on that.