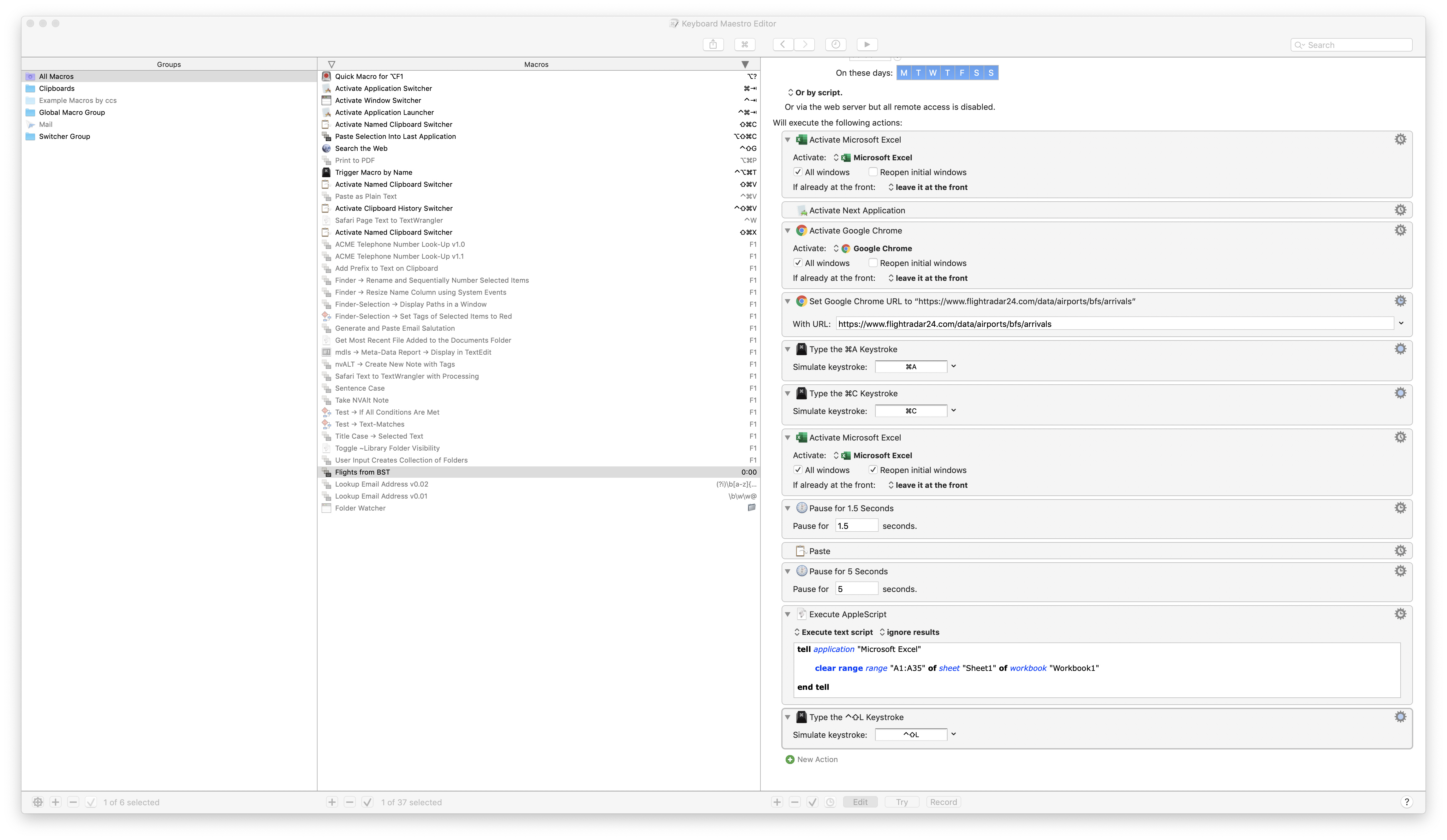
Okay, so I threw together the quick example below. Unfortunately, FlightRadar loads those tables with Javascript, so just using the “requests” python module to get the HTML isn’t enough. I’ve had to change to using Selenium to actually launch Safari, load the page, and then get the source.
That said, it seems to work. It creates an Excel file, with most (if not all?) of the formatting you’ve asked for, and saves it. It doesn’t actually do the emailing, in hindsight I think that’s better off done with something external rather than setting up an SMTP server for Python to use 
Let me know if you have any questions. It’s written for Python3, and you need to install xlsxwriter, selenium and bs4. I did that using pip3, which you can install with Homebrew, and then run pip3 install --user xlsxwriter selenium bs4.
Obviously, any of the code can be changed to suit your needs if necessary.
#!/usr/bin/env python3
import datetime
import time
import xlsxwriter
from selenium import webdriver
from bs4 import BeautifulSoup
EXCEL_FILE = 'flights.xlsx'
URL = 'https://www.flightradar24.com/data/airports/bfs/arrivals'
def main():
with xlsxwriter.Workbook(EXCEL_FILE) as workbook:
worksheet = workbook.add_worksheet()
row_height = 20
font_size = 16
big_font_format = workbook.add_format({'font_size': font_size})
date_format = workbook.add_format({'num_format': 'yyyy-dd-mm hh:mm', 'font_size': font_size})
minute_format = workbook.add_format({'num_format': 'hh:mm', 'font_size': font_size})
bold_format = workbook.add_format({'bold': True, 'font_size': font_size})
# Freeze the first row
worksheet.freeze_panes(1, 0)
# Define the column headers, make the font and row heights bigger
headers = ['Time', 'No', 'Airport', 'Code', 'Reg', 'Operator', 'Time Between Flights']
worksheet.set_row(0, row_height)
# Write the headers to the first row (row 0)
for col, header in enumerate(headers):
worksheet.write(0, col, header, bold_format)
# Initial column widths
col_widths = [25, 5, 10, 7, 5, 10, 25]
soup = False
# Fire up Selenium to fetch the website
with webdriver.Safari() as driver:
driver.get(URL)
# Wait for the page to fully load etc (not sure if this is necessary)
time.sleep(2)
# Parse the contents of the page
soup = BeautifulSoup(driver.page_source, features='html.parser')
if soup:
year = str(datetime.date.today().year)
date = ''
row_num = 1
# Iterate over the table rows
for row in soup.find('tbody').findAll('tr'):
# If the row tells us the date, store it for later
if 'row-date-separator' in row.attrs['class']:
date = row.text + ' ' + year
continue
tds = row.findAll('td')
# Skip any rows that don't have enough columns
if len(tds) < 6:
continue
# Skip any rows where the airport is in the United Kingdom
if 'United Kingdom' in row.findAll('td')[2].find('a').attrs['title']:
continue
# Pull out the data we want
flight_data = {
'time': date + ' ' + tds[0].text.strip(),
'flight': tds[1].text.strip(),
'from_airport': tds[2].find('span').text.strip(),
'from_airport_code': tds[2].find('a').text.strip().strip('()'),
'airline': tds[3].text.strip().strip('- '),
'aircraft': tds[4].find('span').text.strip(),
'aircraft_code': tds[4].find('a').text.strip().strip('()'),
'status': tds[5].text.strip(),
}
# From that, format it how we want in Excel, and add the calculation for the last column
cols = [
(datetime.datetime.strptime(flight_data['time'], '%A, %b %d %Y %I:%M %p'), date_format),
(flight_data['flight'], None),
(flight_data['from_airport'], None),
(flight_data['from_airport_code'], None),
(flight_data['aircraft_code'], None),
(flight_data['airline'], None),
('=A{}-A{}'.format(row_num + 1, row_num) if row_num > 1 else '', minute_format),
]
# Calculate the width of the column
# I chose a "magic number" of "number of letters x 1.8" to hopefully be a nice fit
# You can't use "autofit" like Excel does when you double-click the
# dividers, as that's only available when Excel is running
for col, width in list(enumerate(col_widths))[1:-1]:
col_widths[col] = max(col_widths[col], len(cols[col][0]) * 1.8)
# Set some formatting options and write the row
worksheet.set_row(row_num, row_height, big_font_format)
for col, (data, field_format) in enumerate(cols):
worksheet.write(row_num, col, data, field_format)
row_num += 1
# Set the workbook column headers
for col, width in enumerate(col_widths):
worksheet.set_column(col, col, width)
if __name__ == '__main__':
main()