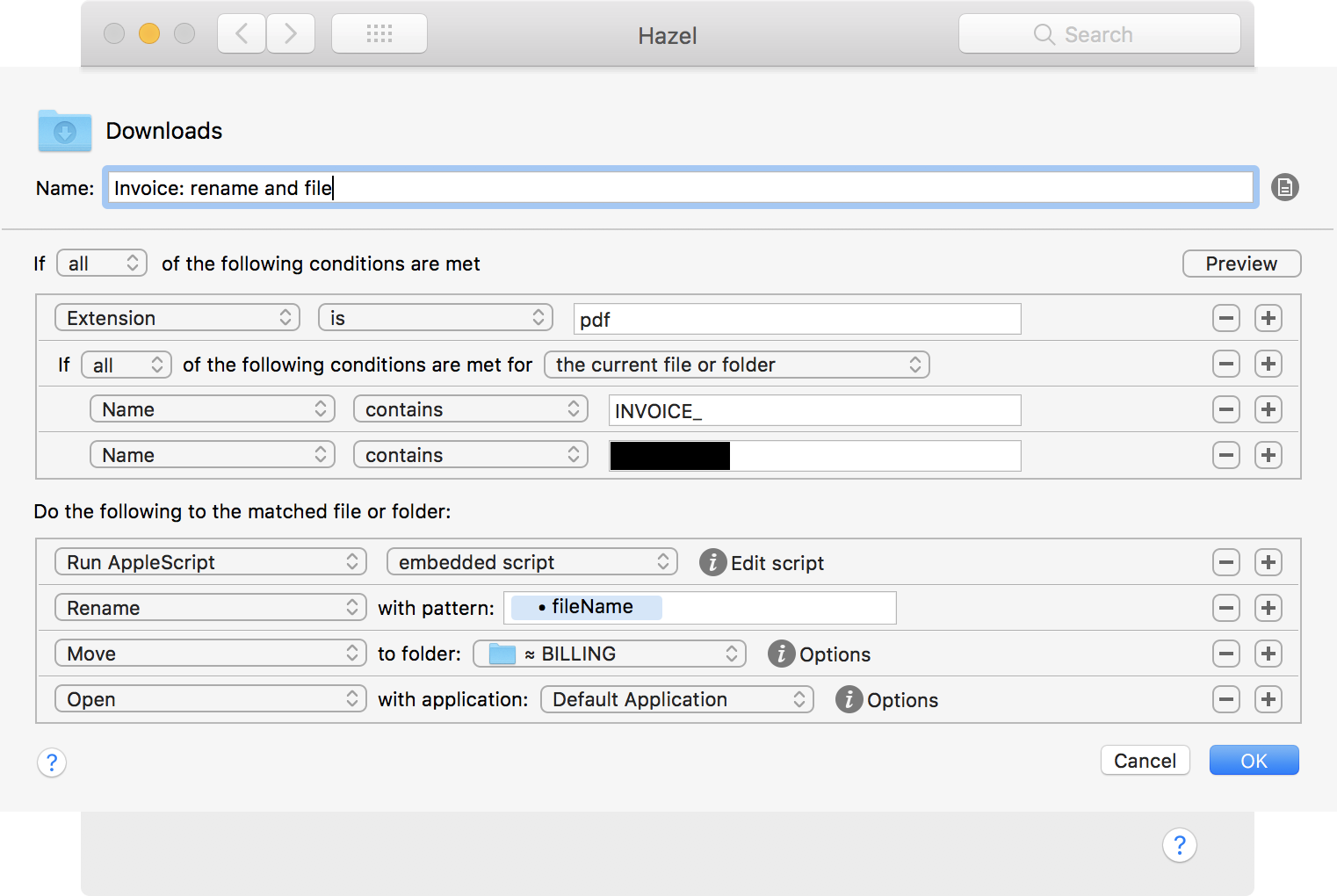
With Hazel I can apply rules to certain PDF files if they contain the text I specify.
I use this for example for Invoices.
What I want to do is create a nice folder with all invoices in order of the month they are for.
Currently I got it to rename the file based on date created (which is diffrent from the date I downloaded it), which works 80% of the time.
But sometimes the date created doesn’t work for renaming (for example when the invoice was created in the next month, but applies to the previous month). I would end up with 2 files having the same name, and have to manually correct this.
In the content of this file there is the correct number to use… Is there any way I can rename the file to some field that can be found in the content?
I use a similar rule to rename and file invoices when they land in my Downloads folder, and then open them for printing.
I solved that problem with a command-line utility called pdftotext (part of the open-source XpdfReader), which I call via an Applescript. Here’s the rule:
And the script, embedded in the first line of the rule:
set itemPath to quoted form of POSIX path of theFile
tell application "Finder" to set fileName to name of theFile
set clientLine to do shell script "/usr/local/bin/pdftotext -raw " & itemPath & " - | grep 'Invoice For'"
set clientName to ((characters 13 thru -1 of clientLine) as string)
set clientName to do shell script "echo " & quoted form of clientName & " | sed -e 's/ //g'"
set fileName to do shell script "echo " & quoted form of fileName & " | sed -e 's/Creative_Q/" & clientName & "/g'"
return {hazelExportTokens:{fileName}}
I don’t know if there’s an easier way to do this, or one without script dependencies, but this has worked reliably for me.
I use dates within the PDF and renamed the file based on the date format. David Sparks’ created a short video on how to do this. That is where I learned it.
The rule is something like Contents, contain match, select custom date, enter a name (I use Date matched), uncheck detect date automatically, find the date you want to identify and use the same format used in the file (you can also type slashes, commas, and spaces as needed), click ok.
Then on the rename make sure to select the “Date matched” that you created above and then whatever else you’d like to rename. Hope I’m clear on this and don’t confuse you. Look for that video, it is super helpful.
Here’s something I am wondering if/how Hazel can do. In my work as a trial court judge, I often create multiple scheduling orders using Word and Excel to create a mail merge document as a PDF file. I then separate the individual orders by dragging the two pages in the order to the desktop. What I’d love Hazel to do is to “read” the contents, identify the case number in the order and then rename the file to match that case number. To be specific, near the top of each page in the caption (Party A vs. Party B) there will be a case number like 1906 PL 501. The next PDF might be 1906 PL 609. As I drop the new PDF file containing only 1906 PL 501 into the Hazel-monitored folder, I’d want Hazel to rename the file to 1906 PL 501 (or whatever the case number happens to be).
Something like this could be useful for anyone who might want to rename PDF files based on say an author’s name for academic articles etc.
I’ve hunted around but can’t seem to find any examples. The AppleScript stokini uses looks like it could be a start, but I could write everything I know about AppleScript inside a matchbook cover.
Ideally I’d like to find a resource online that can show me how to do it so I learn something. Then if I run into problems I could ask questions on this site.
I just saw a post in another thread that mentions Hazel fetching info out of a PDF file, so it apparently can be done. I’ve asked that post author what his rule looks like. I’ll share here when I find out.
Stephen,
Thanks for your response. Actually it is a PDF file. It was a receipt generated from the “Save as PDF” in the print dialogue. So I thought it was strange. Perhaps I need to open and save it in Acrobat or pdfpenPRO?
Based just on that log content, the log looks to me to indicate it is working on a different file to the PDF you think it should be.
Could you share the details (screenshots/code/etc.) of what you have set-up on your Mac? Maybe there is something in your trigger or script that is targeting something other than what you want it to?
@sylumer: Stephen your comment caused me to go back and take another look and you were correct. I was working on a list of items and could not see the text files from a script I ran earlier in the day. You nailed it. Thanks!
Greetings, could someone break it down for a dummy again: I want to rename PDFs within subfolders of a folder by occurrence of a certain text within the PDFs themself. I.e. if the PDF contains “PayPal” i’d like to add PayPal to the filename. How exactly does one go about this with Hazel5 (or anything else, actually)? Thanks a lot. A