I am just now starting to get my feet wet with Hazel.
My first real setup is part of a larger contraption, where Integromat saves Invoices mailed to me to a folder.
I then have the attachments as PDF and the message as an HTML or TXT file.
Now I would like to convert the HTML to a PDF, such that the images will continue to work in the future.
I have tried different methods using pandoc, wkhtmltopdfor cupsfilter but none of them get it right. They either fail, have weird formatting or include wrong characters.
Does anyone have an idea how I can properly archive my HTML files as PDF, automated with Hazel?
This is very difficult to answer without an example HTML file to be able to see where pandoc, wkhtmltopdf and cupsfilter are falling short.
However, if these are invoices, I can understand that you may not want to share them. Perhaps you could copy them and modify the HTML such that it no longer contains actual account numbers or other sensitive information (just remember not to delete that information but change it so we are still working with a document which is roughly the same as the original).
Converting HTML to PDF is difficult because PDF has constraints that HTML does not have, so there may not be a perfect way to do it.
In the absence of a test file, I think my first attempt would involve using pandoc to change the HTML into Markdown, and then convert the Markdown to PDF. My assumption being that the conversation from HTML to Markdown would delete a lot of “cruft” in the HTML which might be what is causing the formatting issues later.
Thanks for the input.
All of the invoices were extracted from an email body and they were very diverse.
From Amazon orders to Apple Invoices, Paypal, Contabo, Hetzner.
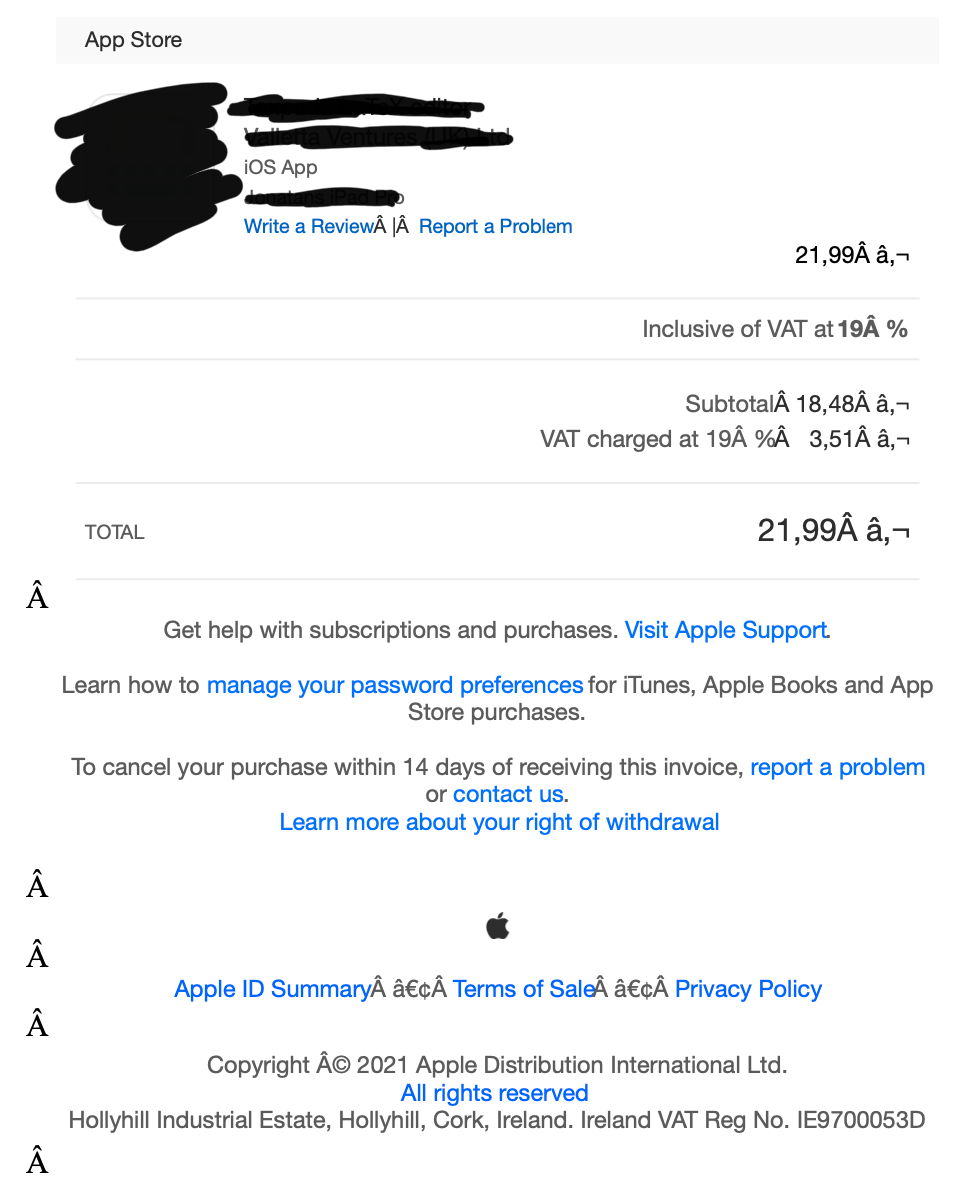
I tested around some more and wkhtmltopdf seems to generally get most things right.
The only one were it falls majorly short is with Apple App Store Invoices (and thus one of my major file sources), where something seems to be wrong with the char set
I suspect maybe it has to do with it using an older version of Webkit, but I’m not sure.
I’ve been fighting with the utf8 encoding for the filename, but didn’t even think about it with pdf conversion.
That fixed it, the output looks perfect.
Wow, I’m so excited that this is starting to work as I want it, now onto putting it all together in Hazel