Now this tool requires me to pass a glob pattern like “*.pdf”, so I can’t pass the filename that I get from Hazel stored in $1.
Ok, just when I have written this down I realize that Hazel passes the filename via $1, and my tool rename which is a Perl tool, uses $1, $2, $3 as group captures in Regexes.
Is there anyone aware of an alternative tool that regex renames files, and that I can use in Hazel?
Is there a reason you aren’t using Hazel to do the renaming? If the filename as are consistent, you could match the pattern in the filename using Hazel tokens and use the tokenized matches to do the renaming.
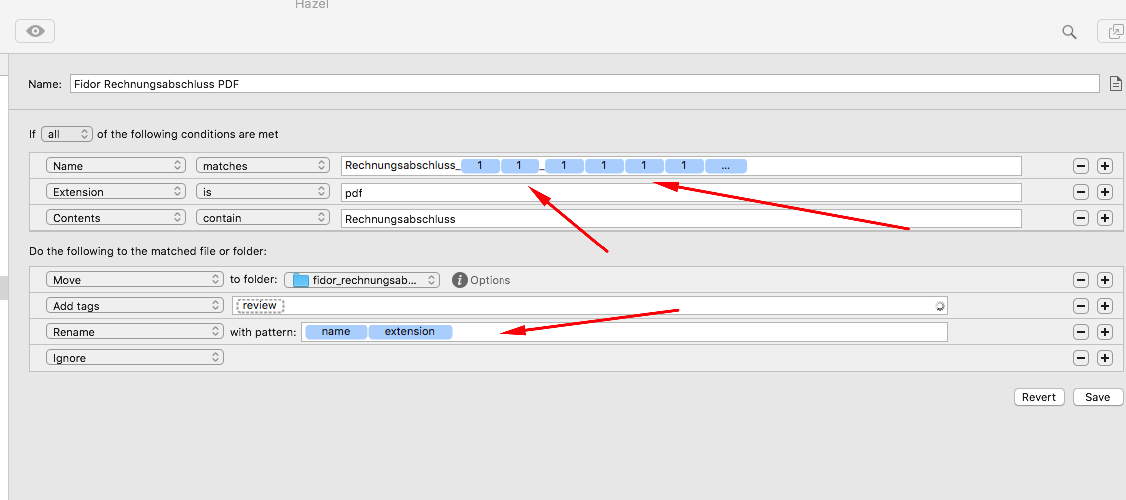
Here [1] I have seen that I can match tokens in the name. Please have a look at my screenshot. - But how do I reference the tokens in the “rename” part.
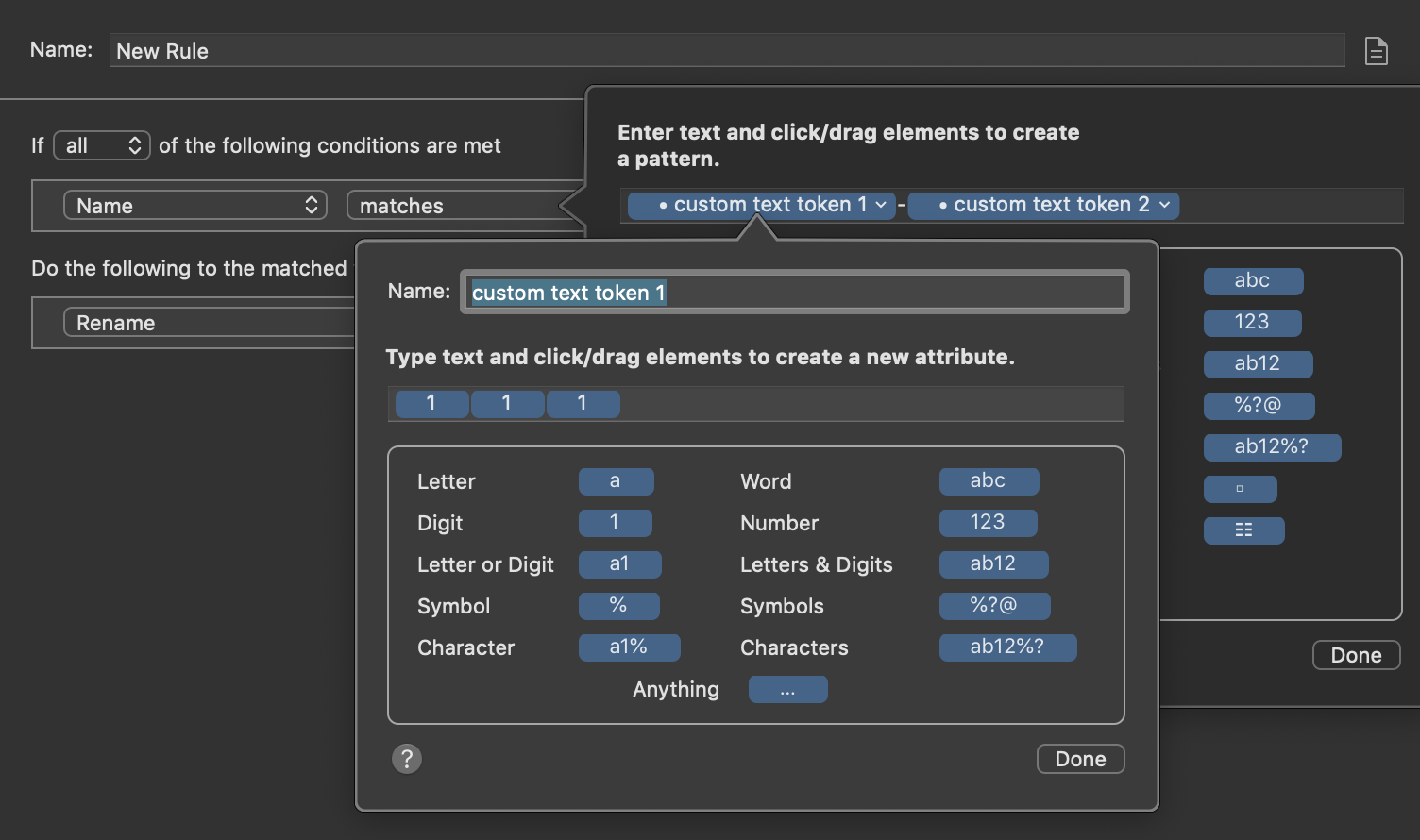
I would suggest using the “Custom Text” token for the matching, and then inside each Custom Text token, you can match each individual pattern group you want to re-use for the renaming.
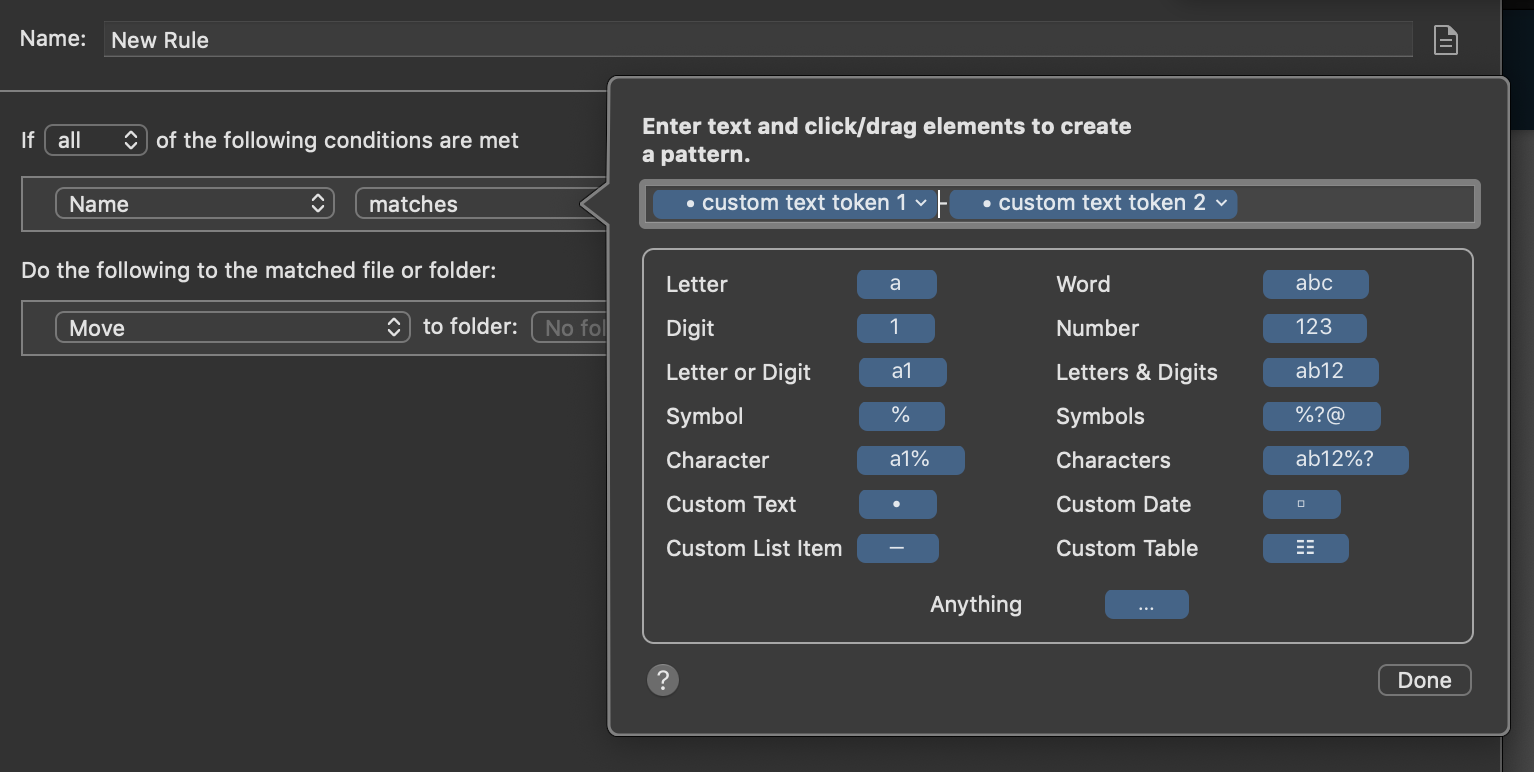
This shows how you can match two pattern groups in the same filename, to use each pattern group separately later on in the rename action later. Just create two separate Custom Text tokens, each with whatever pattern group they need to match. The tokens themselves have pattern within them, and then anything else in th filename not to be re-used later (anything you have not matched with a Custom Text token) needs to be matched literally in the field (things like dashes, spaces, and text to b discarded once renamed).
Int he rename action, now you can arrange the Custom Text tokens you built earlier into whatever order you wish. This method allows you to group each of the patterns. So for every group of text you wish to re-use, create a new Custom Text token, and within the token editor, match that group’s pattern. That keeps each group discrete for use later on in the renaming.
Glad to help. The “matching in the pattern group inside the token” aspect isn’t obvious on first glance. I recall struggling with the same thing you are aim to achieve.
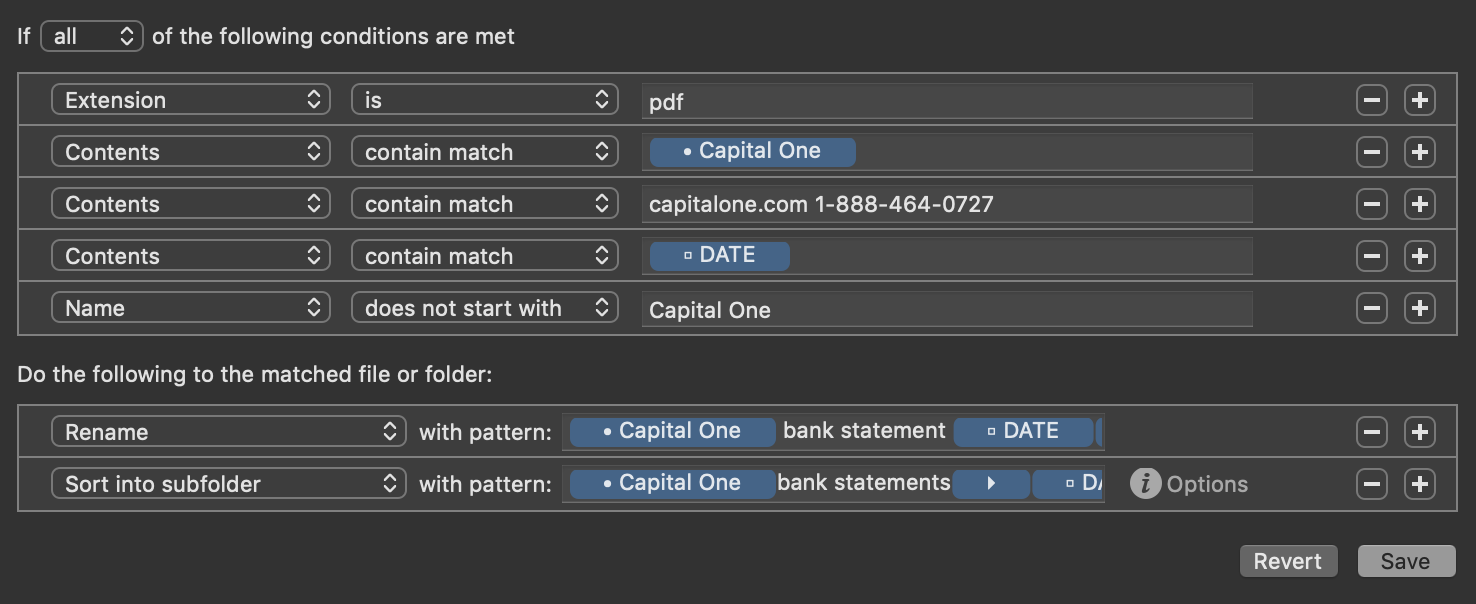
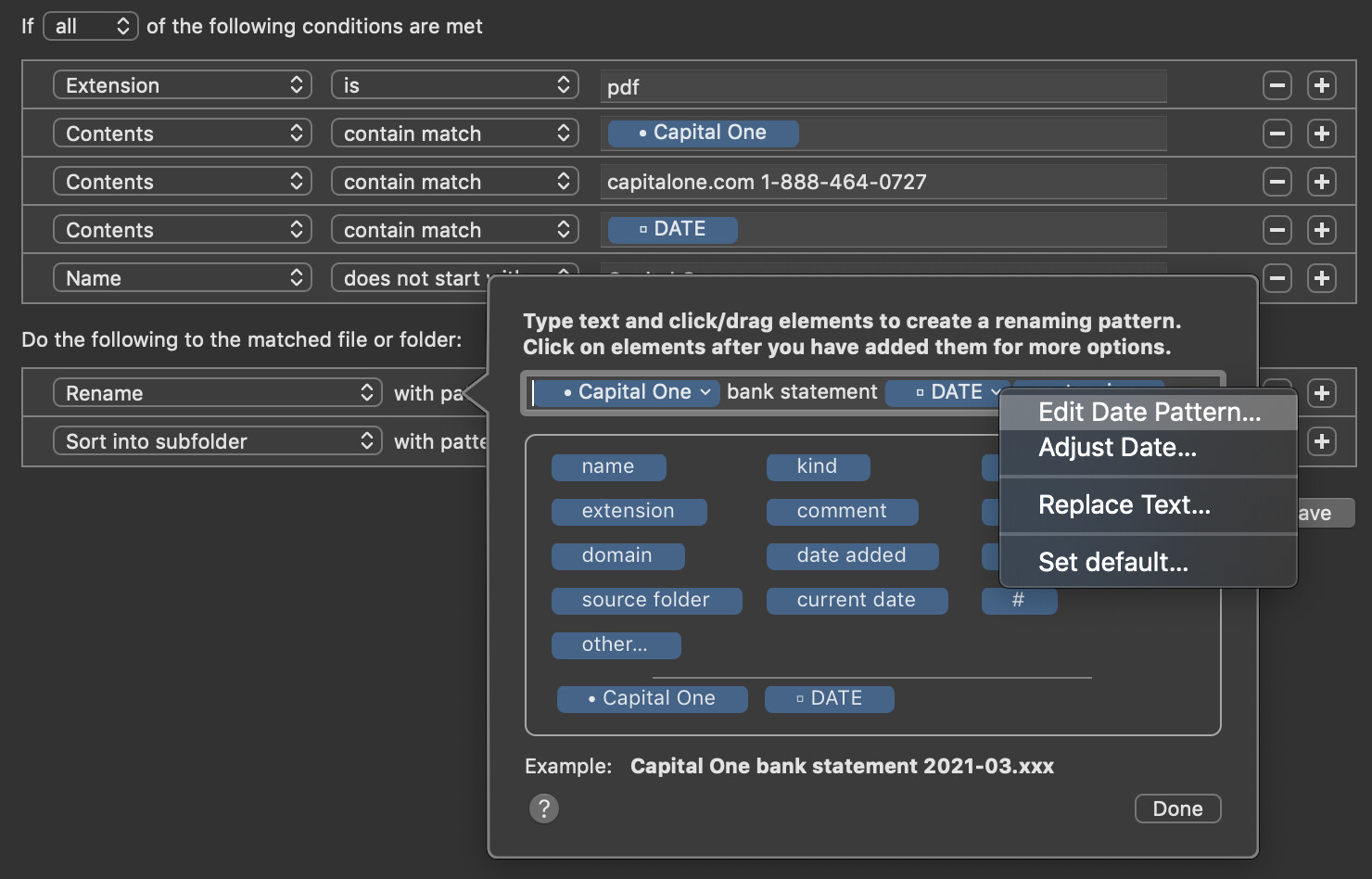
But this opens up lots of cool stuff with Hazel now that you know how to do this. Especially with rules that use “Contents contain match”, because then you can dig into the file and rename/sort using file contents and such, not just the filename. It’s very handy for pulling bank statement dates from inside the contents of a PDF for example.
I get a lot of bank statements that are just named “statement.pdf” or something equally useless. I use these types of rules to dig into the contents, pull out the bank name, the statement dates, etc, and rename/sort using the tokenized info I pulled out of the contents.
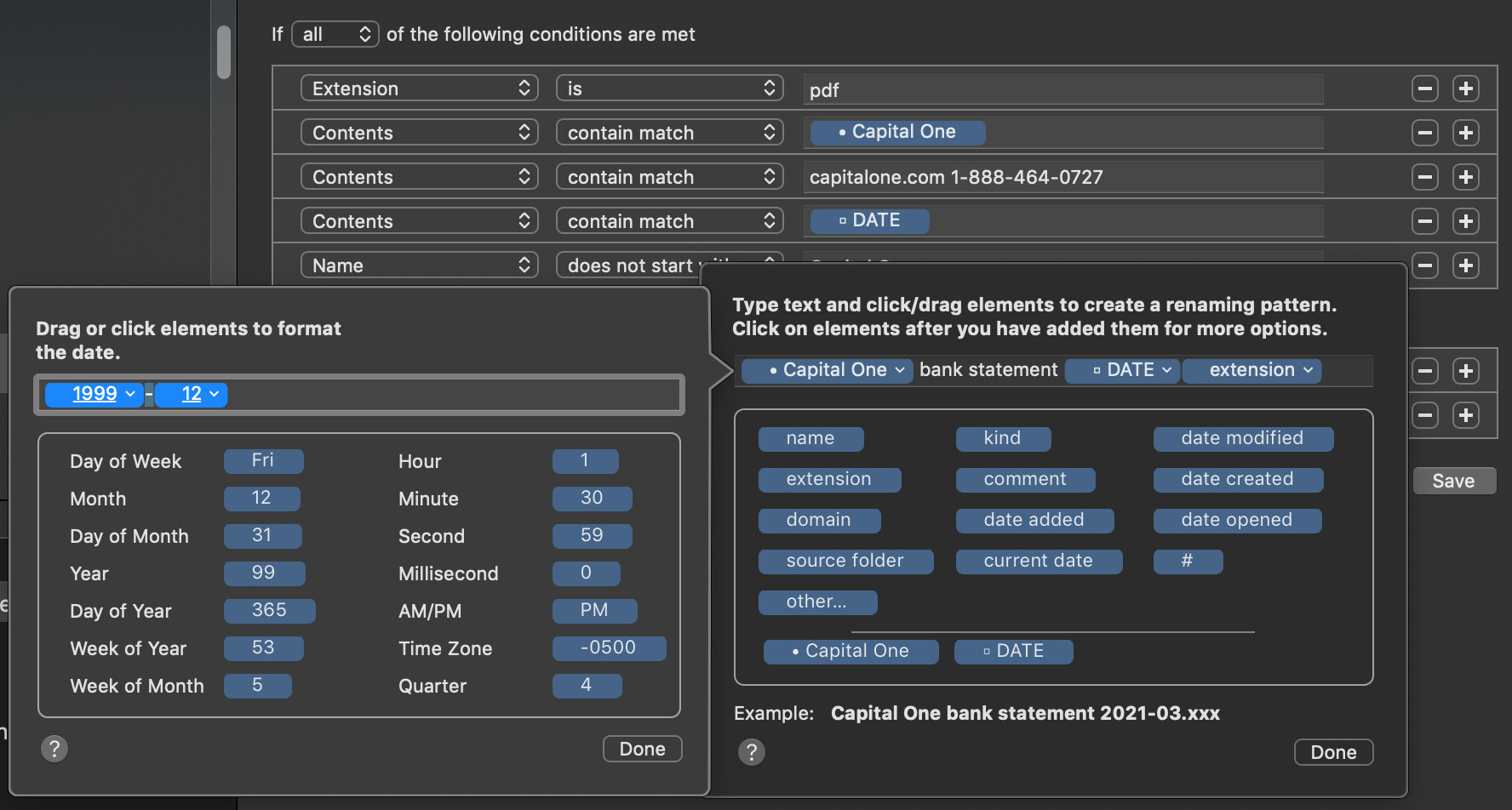
Be sure to look into how the date detectors in Hazel can be used to reformat dates to your liking. For example, if the bank statement PDF displays the date as “March 3, 2021”, you can have Hazel detect the date as-is, and when renaming, use “2021-03-03” or whatever date format you prefer.
There really need to be a good HOWTO on this, because I’ve used Hazel for ages and I still don’t really understand how to do renaming of the filename based on things I find in the PDF.
You would use the same setup I showed earlier in their post, but the rule would be: Contents [contain match], and then the pattern to match is built as a token using the Custom Text.
There is also a rule criteria that is just “matches”, but it seems to not work with file contents quite often, and even the developer on the Hazel forums has suggested to use “contains match” in those cases. Seems it has something to do with how macOS parses file contents.
I can post some screenshots of rules I use to do,this, for reference.
I don‘t know how much I can thank you. With your infos I have rewritten all my rules in Hazel. I‘ve had that tool since 2015, but only now I start to really use it, and it transforms my whole document workflow. Thank you very much!
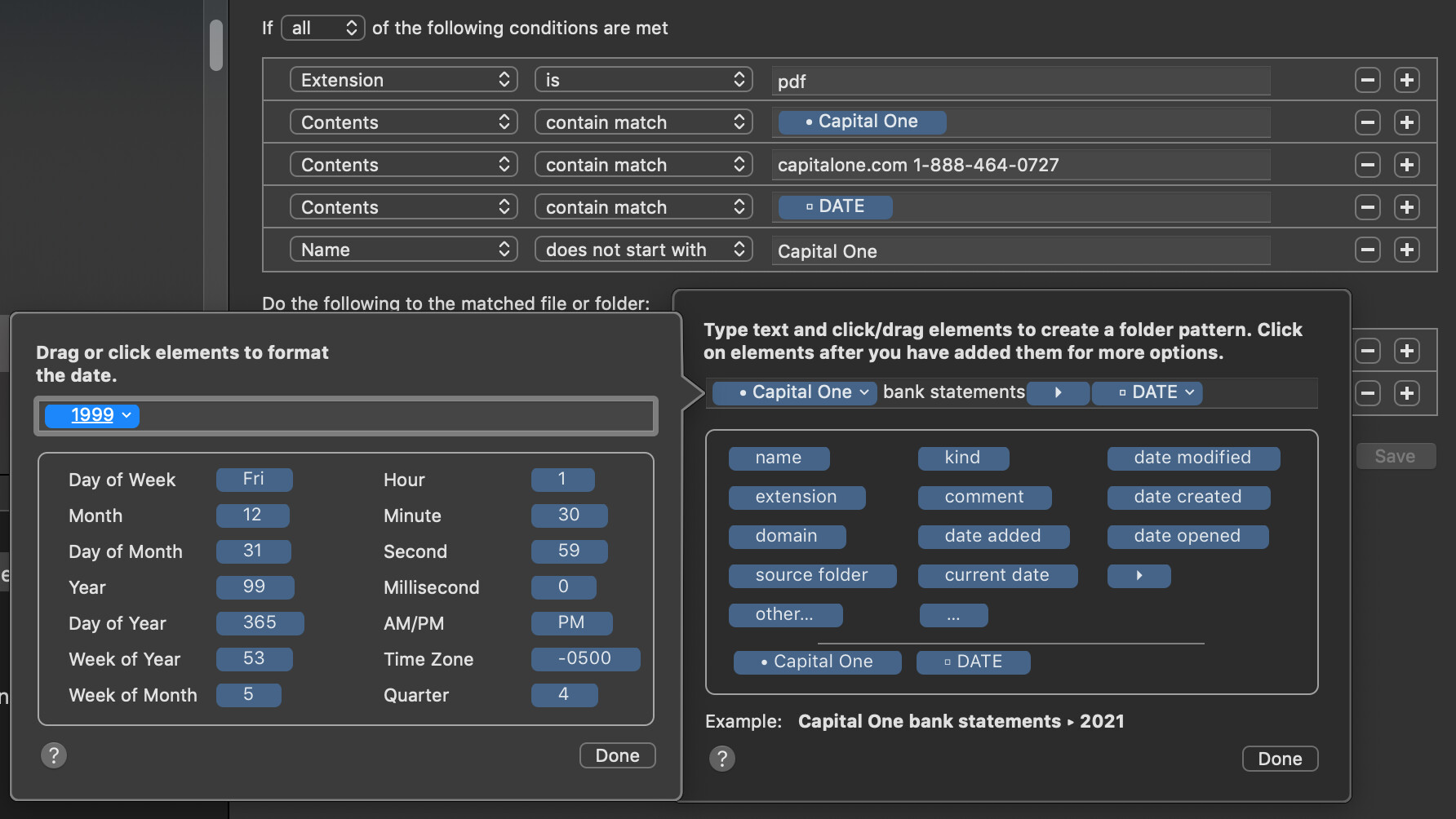
Another useful thing I do with tokenized matches is to match to dates in the filename or file contents, then use those tokens to set up filing these banking PDFs into yearly subfolders.
If the matched/tokenized info is a date such as “March 2021” or “2021-03”, I can have Hazel reformat the date to just use the Year in the subfolder name.
I use the “sort into subfolder” action, and the “create subfolder” token (looks like a right-facing arrow) to sort the PDF statements into yearly subfolders using the date (by reformatting as year-only) that I matched in the contents.
Notice how I am using the same DATE token (which was captured from the file contents) in both the rename filename (which uses year-month), and the year-based subfolder (which uses year-only).
What I did was use the “Edit date format” token menu item (click on the down chevron on the right side of the token), and in the filename I formatted the date as YYYY-MM, but for the subfolder I just used the YYYY because I only wanted to sort by year.
That way, you ensure every file gets sorted the exact same way, pulling the date info from the document itself.
MacSparky’s Hazel Field Guide is a great primer for someone who is new to Hazel, knows a bit but needs guidance, or needs ideas on how it can be extended to do some pretty amazing stuff. The Hazel forums have lots of great workflows and allow direct interaction with the developer. Given that Hazel can also use AppleScript, there really is no limit as to what it can do.