I have long used John Gruber’s TitleCase.pl script to convert text strings to a proper title case.
The way I use it works like this:
- Select some text.
- Hit a keyboard shortcut.
- Selected text is passed through John’s script, and the replacement text is pasted in place, replacing the selected version.
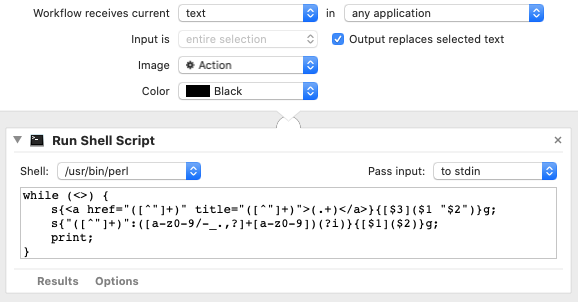
All of the hard work (special cases, etc.) is in the Perl script. The Mac automation is extremely simple, just a Quick Action created in Automator to run the perl script on standard input, and then replace the selected input text.

I also add a keyboard shortcut for the quick action, in System Preferences > Keyboard > Shortcuts > Services.
I’d like to create a similar script, for different text processing. The basic idea would be the following:
- Select some text.
- Fire the quick action on it.
- The script takes the text, and uses regular expressions to match specific possible patterns.
- If it doesn’t match the first pattern, it tries the next, and the next, in a loop.
- If it finds one of those patterns, it uses a substitution pattern to alter the text in some way, returns that text, and stops trying to match patterns. (Think
breakin a loop.)
My specific use case is that I’m cleaning up a lot of old content that used multiple different formats for creating links. I want to select an existing link, run the quick action, and output a modernized version of the link.
Here’s two examples of substitutions I want to do:
Textile link to Markdown link
"([^"]+)":([a-z0-9/-_.,?]+[a-z0-9])(?i) ➜ [\1](\2)
"Regular" HTML link to Markdown link
<a href="([^"]+)" title="([^"]+)">(.+)</a> ➜ [\3](\1 "\2")
I would love to just re-use TitleCase.pl shell with some changes to handle the find/replace pairs, but that Perl is … I’m not a Perl guy.
This seems like such a straightforward and generally usable tool that I was hoping to find something ready-made here on Automators. But I didn’t find anything that looks likely.
I have no specific interest in using any scripting language to do this. Perl is great, Ruby is great, COBOL, whatever works.
I don’t really need help with the regular expressions part. My examples aren’t particularly solid, I just knocked them out to have something to write the rest of the script with. They can definitely be improved, but the problem I have is putting them into a script that can use them.
Anybody know of a good example of doing this?