Hi Guys,
I found some topics about Hazel and OCR but it seems like most of you are using PDFpen Pro to get the OCR layer.
I wanted to ask if someone has a free tool which can accomplish the same. I dont need a new PDF editor, because I have PDF expert and it fits for everything I want to do, exept the OCR thing. I already mailed them but as far as i know this feature is not available.
What I want is (maybe a terminal tool - I think there is something available with brew) a tool which can apply the OCR layer in the background.
I tried using Tesseract for a workflow when I was trying to replicate Evernote’s ability to scan images for words. I switched to a Devonthink Pro workflow because Evernote got creepy. It worked okay, but it was not the most accurate tool for my task.
Not free, exactly, but I played around with Prizmo, which is included in SetApp, for this. I did get something working at the time (this would have been about a year ago now) as the app has an Automator action. However it took FOREVER to run and I never took the time to look into it further.
PDFPen is included in SetApp now too, though, which may mean the above is irrelevant—being currently Mac-less I haven’t looked at it again.
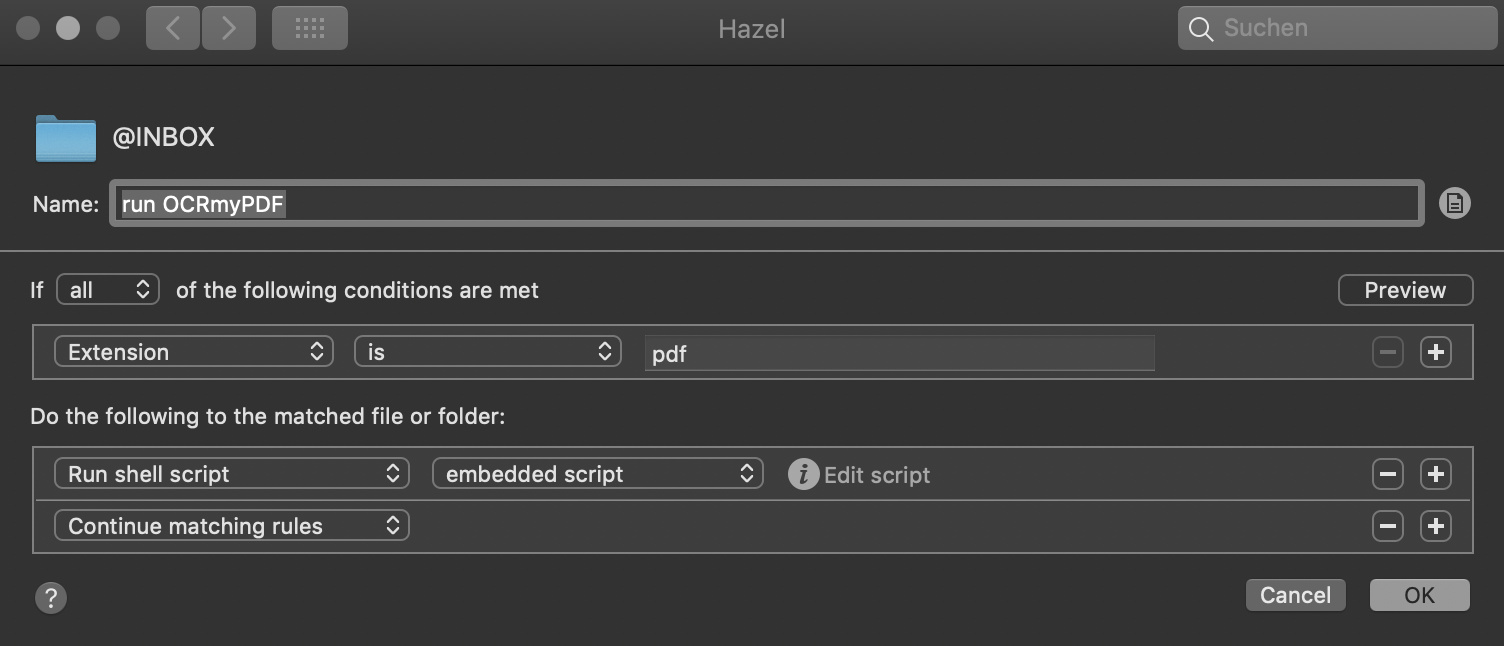
For anyone interested,
thanks to @tbrown313, I installed OCRmyPDF with homebrew (HERE is the instruction).
to automatically scan the incoming PDFs I created the following hazel rule:
the --skip-text jumps over every page which already contains text (scans from my iPhone already contain a OCR layer).
you can change the languages (in my case German and English) according to your personal needs.
Is anyone still using this? I can’t seem to get the embedded script FlohGro typed up to work. The log doesn’t give me anything useful: Shellscript exited with non-successful status code: 127.
Yes! It works great as a command in the terminal, just not as a script in Hazel. It seems like (the error) has something to do with the file referencing “$1” “$1.” Is it still working for you?
Thanks for this script, for use together with Hazel is the best option for me. So I did install OCRmyPDF and tesseract as well. But I get anytime an error in the Skripteditor for the part “l deu” (for me as well german and english are relevant, most german).