Hi all,
I have recently bought Hazel and am absolutely loving it!
I’ve set up a rule to process my payslips, but when I download the payslip the name comes in a messy format, like this:
Q000190A.2018614.122516.0001726065.pdf
I’d like to extract the date portion and keep only the year and month (I am paid monthly), so the file name in this case would be “20186”, or more complex and ideal, 201806 (inserting a 0 if the number is less than 10).
I’m thinking I can do it in Automator and then run that script in Hazel, but have no idea where to start!
Thanks!
I’ve never used Hazel so I’m not sure what one can do with it, but assuming the date is always in the same spot in the filename,
Here's what the logic could be like in Python
import re
string = "Q000190A.2018614.122516.0001726065.pdf"
matches = string.split(".")
date = matches[1]
year = date[:4]
month = date[4:6] if len(date) > 7 else "0"+date[4:5]
print(year+month+".pdf")
Or in JavaScript
const string = "Q000190A.2018614.122516.0001726065.pdf"
const matches = string.split(".")
const date = matches[1]
const year = date.substring(0,4);
const month = date.length > 7 ? date.substring(4,6) : "0" + date.substring(4,5)
console.log(`${year}${month}.pdf`)
I think this should do what you want in Hazel on its own.
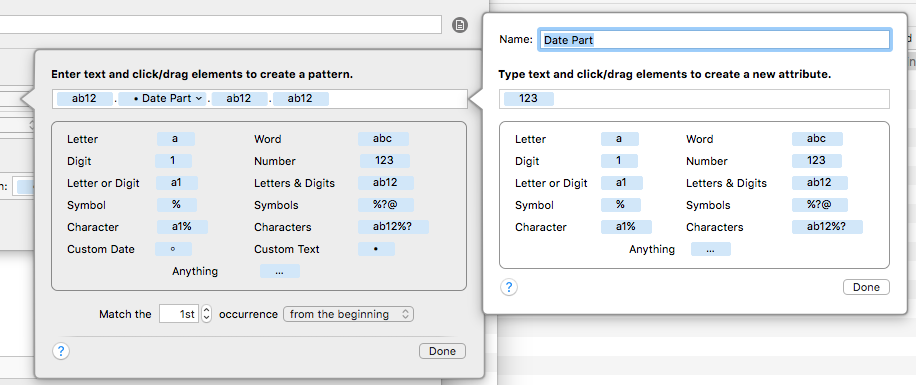
The base rule.
The matching pattern including a token to represent the date section that is used in the rename.
As for including extra zeroes, I don’t actually think that would be possible using any solution. Even the ones provided above 
The issue is if you have a file name like this:
Q000190A.2018112.122516.0001726065.pdf
The question here is which date would it be? 20180112 (12 January 2018), or 20181102 (2 November 2018). There’s no way to determine this unless your file created date might give you a clue or if you are going to use Hazel to scan the content of the file for a pattern match and use that.
The ideal solution of course would be to have your source include a non-ambguous data stamp identifier.
Hope that helps
1 Like